
 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.Introduction
If you have managed a Drupal website with user-generated content or content from API sources over a period of time, you might have found yourself dealing with a lot of unwanted content. Depending on the source of this content, it might be an overwhelming challenge to clean it up and restore the website.
I have found myself in this position a few times throughout my time with Drupal, and I'm going to share a few tips and examples that would help you. For this, I'm going to use the last site I cleaned up as the primary example, and will also generalize the advice for other types of sites.
About contrib tracker
The site in question is called contrib tracker—something that we built in one of our hackathons to track open source contributions from our team members. Since we actively contribute to the Drupal community on drupal.org, we built a component which automatically pulls contributions from there and adds it to our website. It uses a simple mechanism to detect previously scanned issues and comments based on the URL of the issue. The URL was generated by the contrib tracker application in a way which matched the URL on drupal.org, and it all worked.
That is, it all worked until drupal.org rolled out fancier URLs for all the issues, and then the issue URL we generated in the application no longer matched the URL returned by the API. Since contrib tracker couldn't find a node with the updated URL, it kept inserting new nodes. We only detected the issue when the database volume ran out of space and new entries couldn't be created.
In this case, the culprit was a hidden bug in the application which didn't consistently use URLs at different times. In your case, it might be spam from user-generated content, runaway feeds, or any of the other innovative bugs that it is our privilege to introduce. The result is unwanted content, and you want to get rid of that.
Planning the clean-up
Regardless of the reason, we can devise a common strategy for cleaning up the unwanted content.
- Decide whether to freeze the current content
- Identify common attributes of content to clean
- Using attributes from the above, identify node IDs to remove
- Remove references to those nodes and then the nodes themselves
- Validate by repeating the process
Let’s look at each of these in turn.
Freeze the current content
Depending on the complexity of the clean-up operation, and the impact on your users, you may be forced to freeze the current content. Common scenarios for freezing content is where we can’t control the content generation (such as in the case of spam content) and where the content removal may not be automatically automated.
In our case, the runaway content was being generated due to a bug (which we immediately fixed) and we could automate the entire removal. We didn’t need to freeze the content in this case.
Identify common attributes
Here, we define the attributes for what we would consider unwanted content. This varies with use case, ranging from nodes with the same titles, to nodes created by a particular set of users, to spam content.
In many cases, especially scenarios with duplicate content, we cannot just retrieve a simple list of all node IDs which are duplicate. Actually, we can—but a typical database operation would return all such results in one result set, which complicates the operation logic. Considering that content removal is a very important operation, it is okay to have an additional step (or more) so that we can verify the results before identifying the nodes themselves.
In our case, the common attribute was a field which should have been unique, but due to the bug, we had duplicate entries. Our first step here is to find all the duplicate entries. We do this with a SQL query like this:
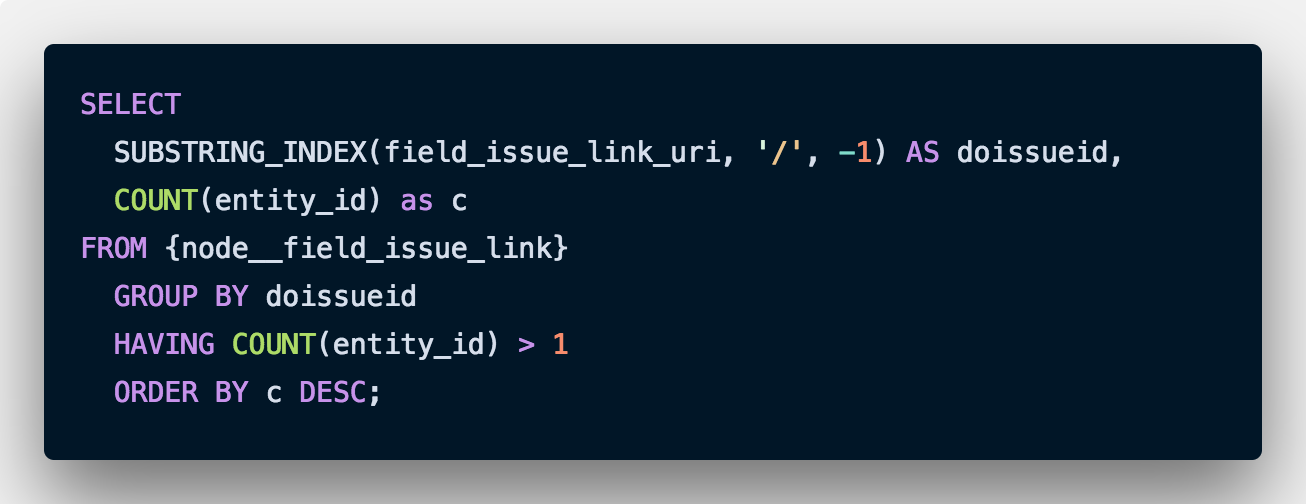
The field in question (field_issue_link_uri) used to hold links like these:
https://www.drupal.org/node/2828952
However, due to the change in API, the links getting saved looked like this:
https://www.drupal.org/project/infrastructure/issues/2828952
The above SQL query would return a list of all IDs (just the IDs, as we are using the SUBSTRING_INDEX function and GROUPing by it). We only need those IDs which are duplicated (COUNT(entity_id)>1), and then we need them sorted by count in descending order (ORDER BY c DESC). We now use this list in our next step.
Identify the node IDs
Now that we have some attributes which we can use to identify content, it is time to identify the node IDs which we need to remove. From the previous step, we have a list of drupal.org issue IDs which correspond to duplicate nodes. We use that to get a list of nodes.
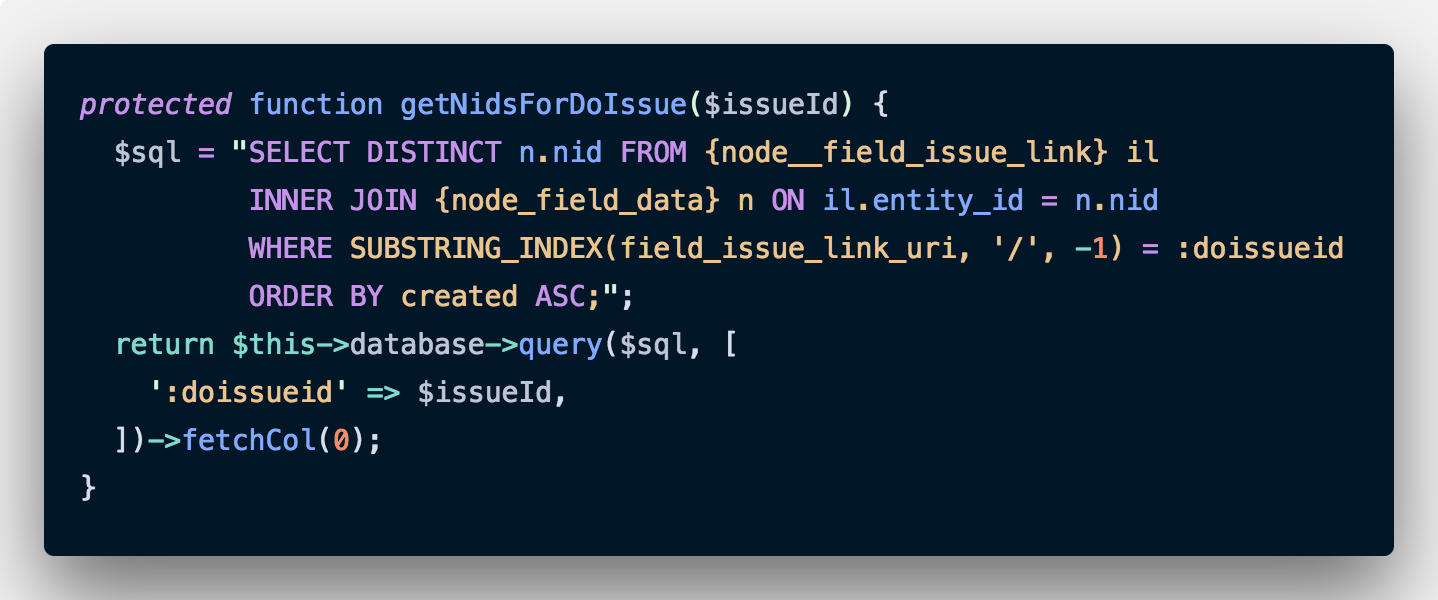
This is relatively simple. We write a simple query to get all those nodes where the link ends with our drupal.org issue ID. We do this one at a time for each drupal.org issue ID. Note that we could have done both these operations in one go and got a list of all node IDs, but doing this makes understanding the code a lot more difficult. For code that needs to be run only once, don’t sacrifice readability for performance. This is especially true for code where effects are hard to reverse (always take backups anyway).
Another important note: The above function returns all the nodes with the drupal.org issue ID. We shouldn’t remove all of these. There is one valid node which we want to keep. In the above case, we are sorting by the node creation date, so that we can keep the oldest one and remove all the subsequent ones. We will remove that node from our list with an array_shift. As a bonus, we get the ID we just shifted off the array which we can use for logging.
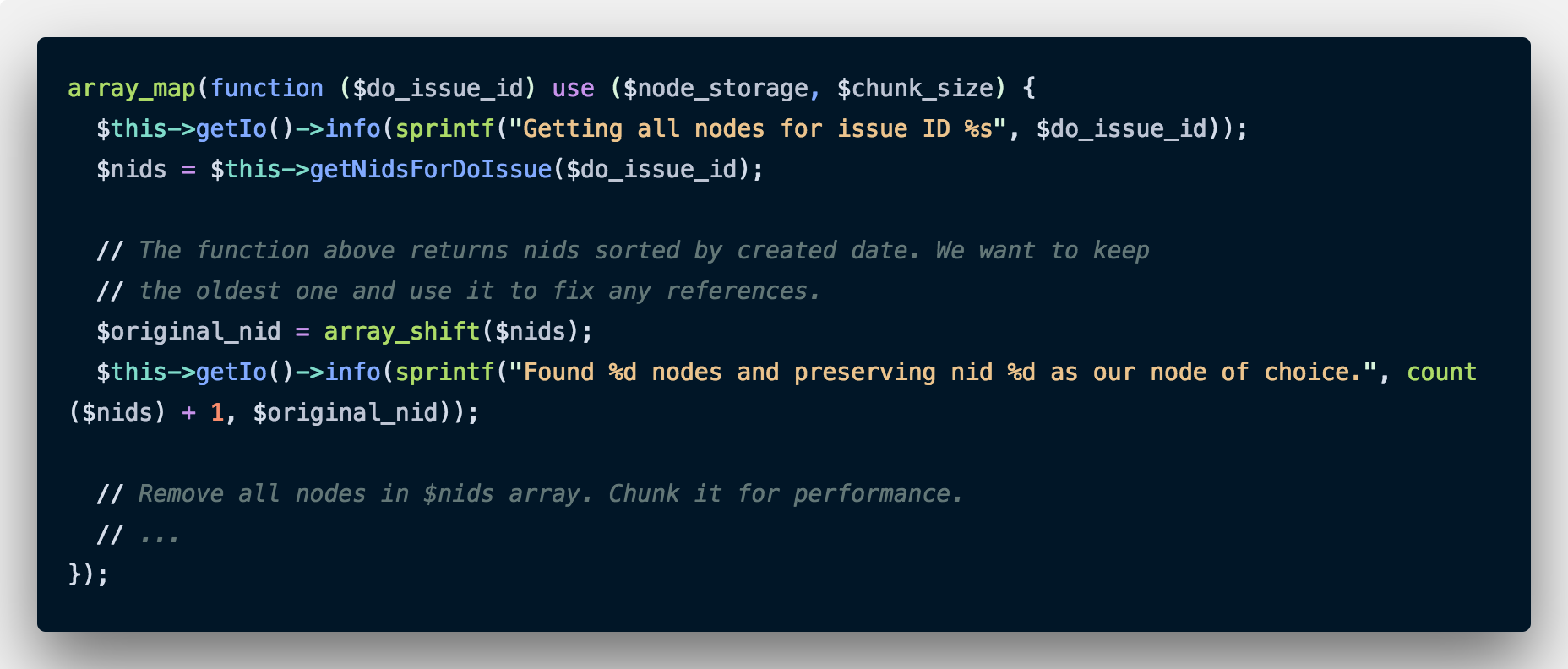
The astute reader may have noticed that we could have just added an OFFSET to the SQL query to get the list of node ids, but we would then not have been able to log it or fix references. Again, I am going to go for straightforward and simple code instead of clever code.
Remove references before deleting the nodes
The complexity here could vary depending on your data model. You may have references to the nodes you intend to remove from other entity reference fields, links, or even links inside content. Depending on where the node is being referenced, you may have to pick a strategy that removes it effectively. As a thumb rule, if a node reference is too hard to remove or update, consider that the node may actually be required and shouldn’t be removed in the first place. Of course, your mileage may vary.
Fortunately in our case, we just have a single code contribution link that points to these duplicate issues. Remember how we obtained the node ID we are keeping in the previous step? We are going to use that now in our new method.
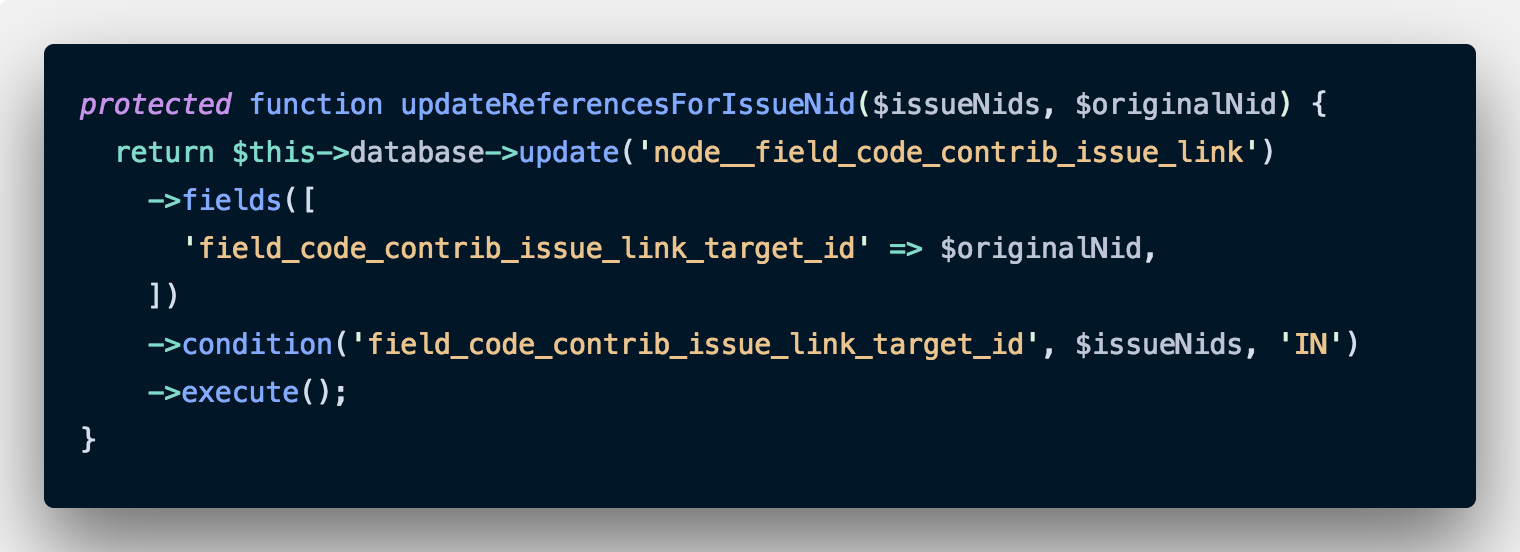
Our reference to the issue is stored in a field called field_code_contrib_issue_link. We are just going to find all the nodes which refer to the list of node IDs we are planning to remove ($issueNids) and going to replace that field with the node ID we intend to keep ($originalNid).
Once this is done, we just delete the nodes. Here is the outer code which calls the above function.
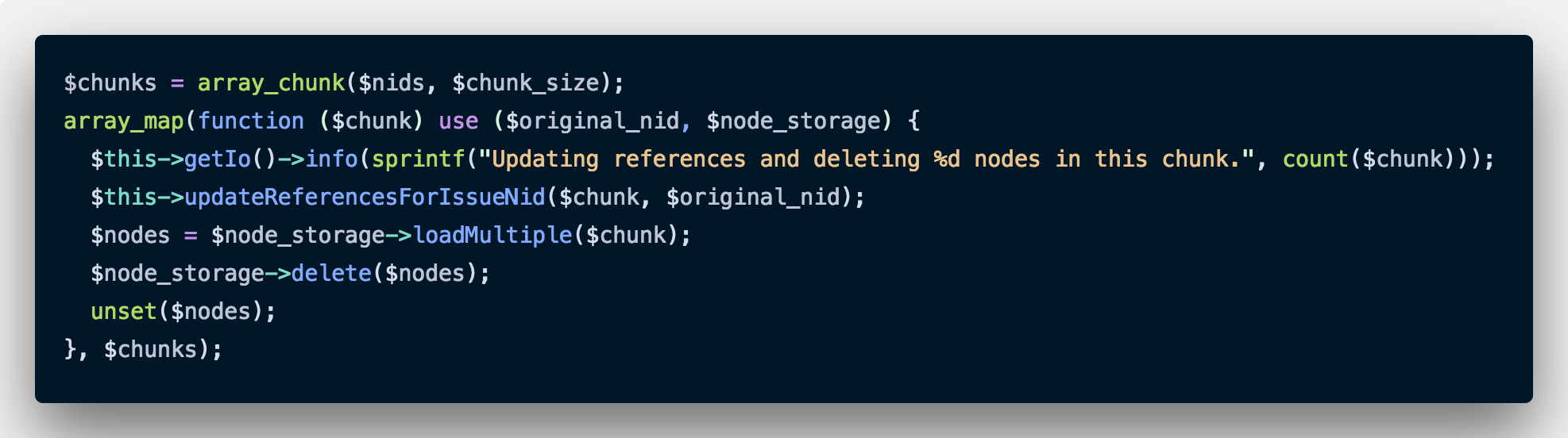
Notice that we are only deleting a few nodes at a time. Drupal has to load all nodes before it can delete them, and we don’t have to load thousands of nodes in the memory at once. After deleting, we unset the nodes array for good measure. We used chunk sizes of 100 to 500 to keep this operation efficient. Of course, your mileage may vary depending on your server’s RAM and CPU.
As an added step, we make sure that the link structure in the node we are keeping is correct (so that the bug doesn’t repeat). This is what it looks like.
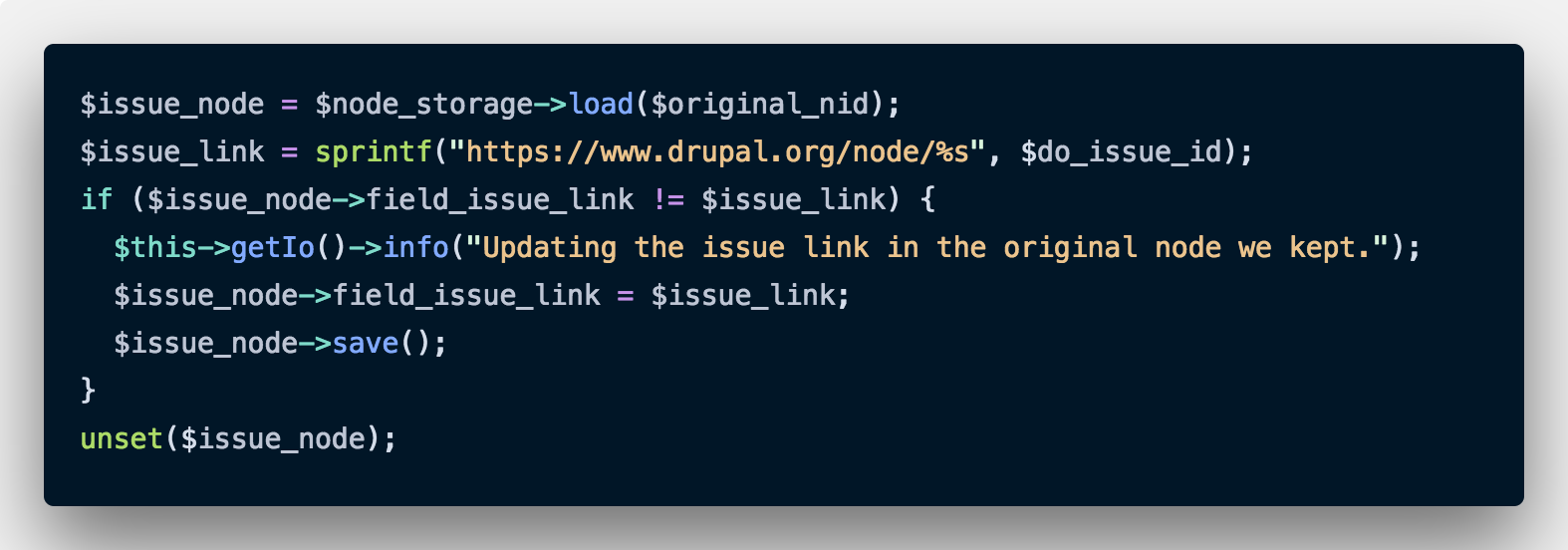
Validate
Run the script multiple times on a test database to verify that it works as expected. Make sure that we are not breaking any references, or removing nodes we intend to keep. I kept running the queries manually in Sequel Pro and observing the results to make sure that the results appeared correct. This is very important. If possible, get someone else to verify the results.
Implementation
Once you have a plan built up, implementation is a straightforward process, but an important decision. If the clean-up is manual, it may be a good idea to freeze the content as we discussed earlier. If the clean-up is automated like in our case, we can write a script and test it on different servers, and once we are certain that it works as expected, we run the script on production. Always take backups!
In case of automated scripts, there are many options ranging from a standalone PHP script which bootstraps Drupal to writing a drush or Drupal console script. In our case, we generated a Drupal Console command using drupal generate:command. This is what it looks like.
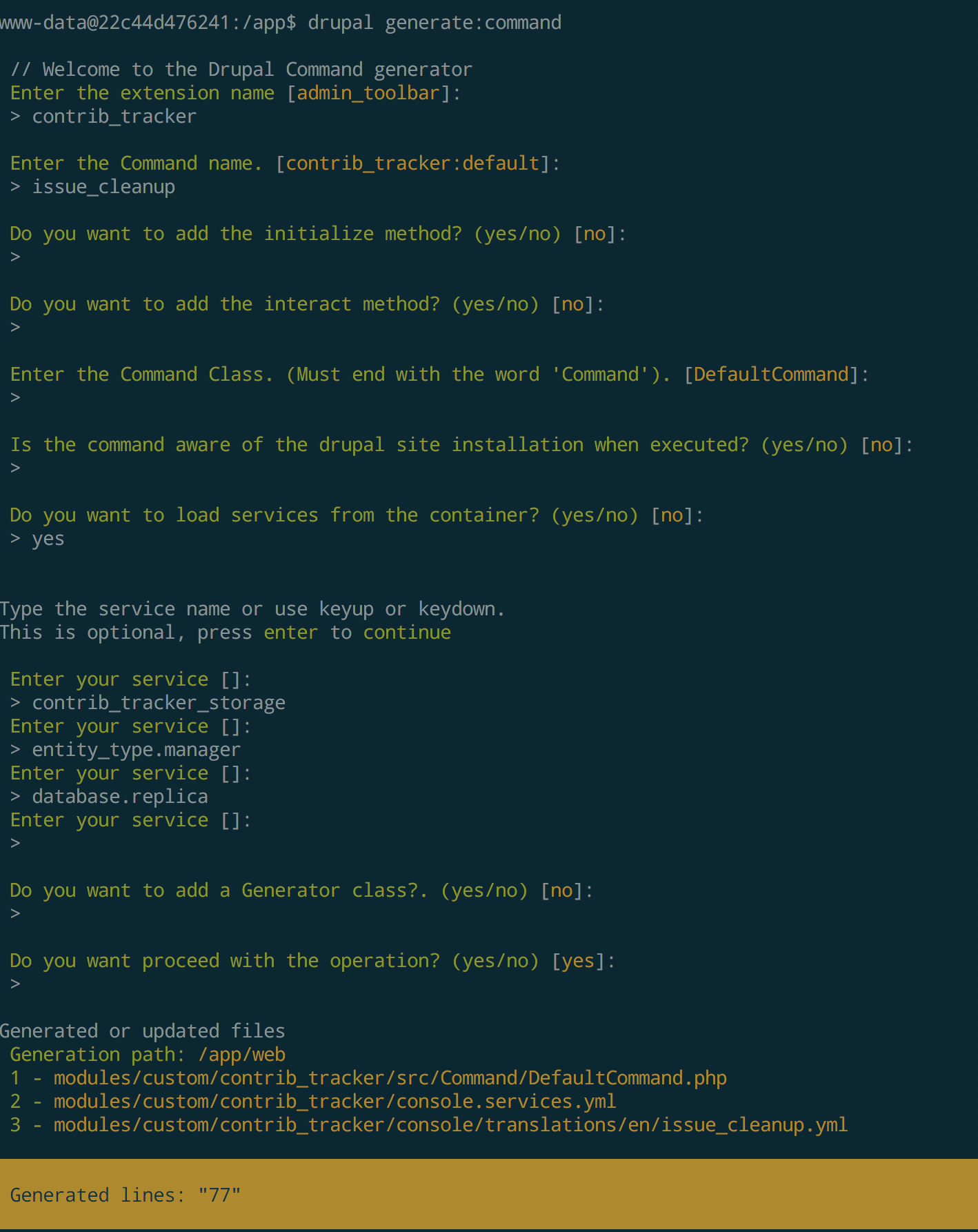
A full discussion of writing Drupal console commands is out of scope here. Please refer to the documentation for more details.
I realize that the code in the screenshots above can’t really be copied, but you don’t have to. This application is entirely open source and available at https://code.axelerant.com/axelerant/contrib-tracker. If you are interested in only the changes specific to this script, please look at this commit.
Conclusion
Issues with content on a live website are always scary, but as long as we follow general principles as outlined here, they don’t need to be. It is important to get the strategy reviewed and validated, and also test. Most importantly, always take backups. I cannot stress this enough.
Content is usually the most important part of your business and it is always a good idea to consult professionals who understand content and Drupal’s content model. Reach out to us.

Hussain Abbas, Director of Developer Experience Services
Hussain is a calm ambivert who'll surprise you with his sense of humor (and sublime cooking skills). Our resident sci-fi and fantasy fanatic.



Leave us a comment