
The Challenge

The Solution

The Result
-
Sub-Second API Latencies at Scale
-
Streaming Rewrite For Platform Stability
-
AWS Governance With Control Tower
-
Event-Driven Aggregation For Real-Time Dashboards
Sub-Second API Latencies at Scale
Axelerant introduced structured performance profiling, rewrote core backend services in Go, and optimized database access with targeted indexing and payload decoupling:
- Backend throughput scaled from 140 RPS to 560+ RPS, validated under live load simulations.
- Key transactional endpoints (e.g., market transactions, odds fetch) were reduced from 2.3s P99 latency to <250ms.
- Multiple layers of latency mitigation were applied, including caching of hierarchical lookups and compression of API payloads.
-1.webp)
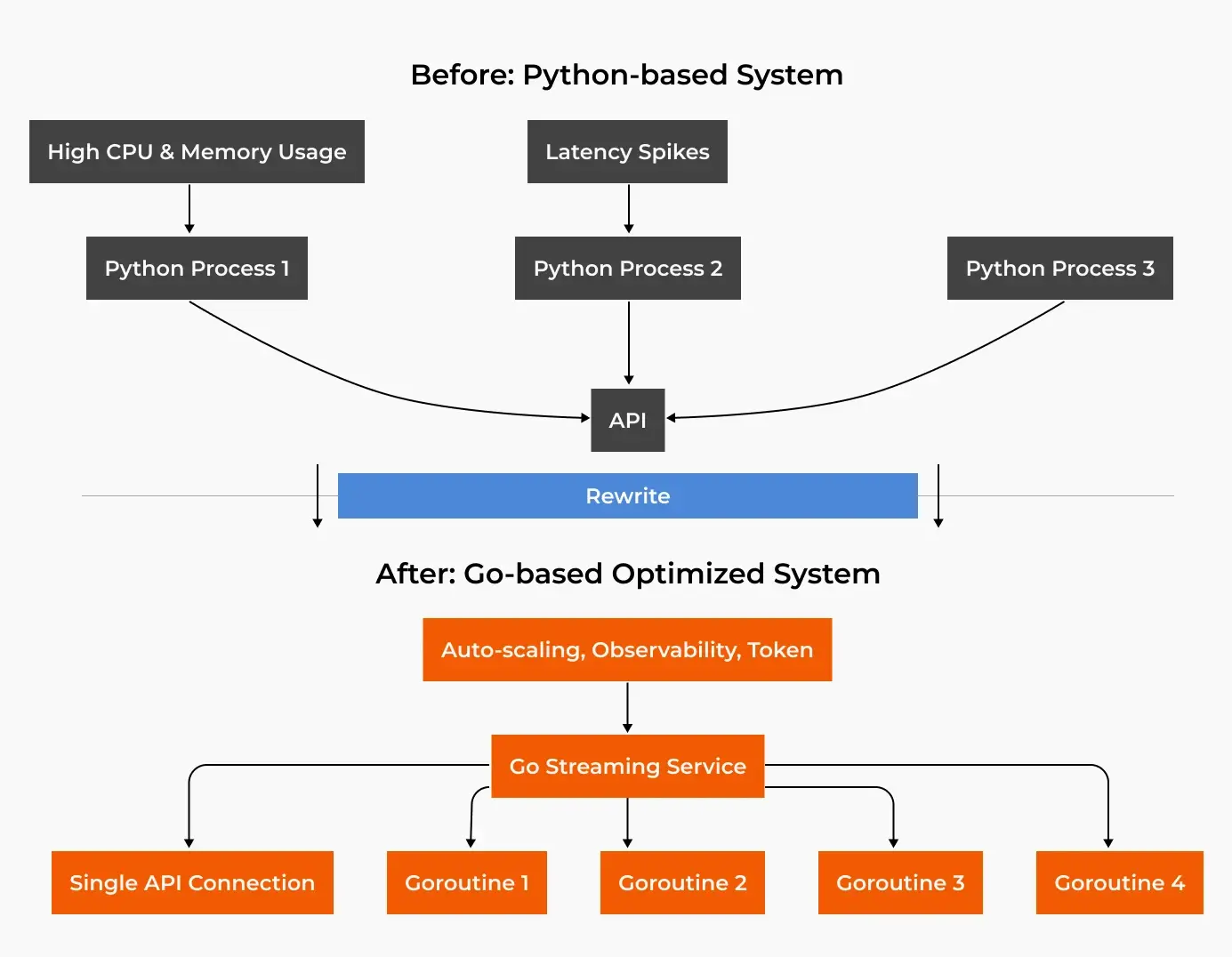
Streaming Rewrite For Platform Stability
The streaming system was completely rebuilt using Go, enabling:
- A single persistent connection via WebSockets with goroutine based handlers for each market stream.
- Memory reduction from 6 GB to 150 MB, and CPU usage from 2.5 cores to 0.1 core per pod.
- Smooth support for 20,000+ concurrent live markets with no dropped connections or missed updates, even under active load.
- Built-in metrics exposed internal state (queue lag, message time skew) for proactive recovery.
AWS Governance With Control Tower
The platform's infrastructure was migrated into a multi-account, highly governed AWS setup:
- Development, production, logging, and shared services were fully isolated.
- Centralized logging, role-based access, and policy guardrails reduced surface area and improved operational clarity.
- Account-specific billing and tagging improved cost attribution per environment and per service.
- Guardrails like AWS Config, and CloudTrailwere activated organization-wide for compliance enforcement.
-1.png)
Event-Driven Aggregation For Real-Time Dashboards
The legacy synchronous aggregation architecture was replaced with a Kafka-based event pipeline:
- Users, bonuses, and referral earnings are now pre-aggregated in real time and stored in durable Redis snapshots.
- Dashboard queries became lightweight reads instead of heavy nested joins.
- A live hierarchy sync mechanism was built to automatically propagate structural changes (e.g., user level changes, new agents).
- Admin dashboards now load in <1 second, even with over 250 concurrent agents and thousands of downstream users querying simultaneously.
-2.png)