
 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.Introduction
At most organizations, matching internal talent to project needs is a high-stakes process handled with surprisingly low-tech tools. Despite the abundance of employee data, resumes, skills inventories, and availability trackers, staffing still relies on a patchwork of systems: spreadsheets, static resumes, self-reported skill matrices, and availability trackers that don't talk to each other. Managers scramble to find the right talent, chasing down updates from HR tools, scanning Slack threads, and guessing whether someone is actually free or a good fit. This is not a minor inefficiency; it’s a structural bottleneck hiding in plain sight.
The impact is significant and often invisible: project delays due to late staffing, over-reliance on a narrow pool of "known" talent, underutilization of skilled employees, and a growing disconnect between delivery needs and staffing readiness. The larger and more distributed an organization becomes, the worse the problem gets.
At Axelerant, we saw this challenge not just internally, but echoed across our clients and industry peers. We knew that solving this required a shift in how talent discovery works.
We built an Intelligent Staffing and Allocation System to close this gap, one that uses LLMs, canonical skill modeling, and vector search to automate the talent matching process. This system transforms staffing from a reactive chore into a proactive, data-informed process.
This isn’t just about operational efficiency. It’s about reclaiming time, unlocking hidden talent, and creating a smarter, fairer way to allocate people across work that matters.
The Problem: Why Traditional Staffing Systems Don’t Scale
As organizations mature, they accumulate disconnected systems for resource planning, skill tracking, and availability. Here's what usually happens:
- Outdated And Inconsistent Skill Data: Most staffing decisions rely on resumes or employee profiles that are self-reported, outdated, or inconsistently formatted. Without a verified and normalized view of individual skills, it's nearly impossible to make accurate decisions at scale.
- Fragmented Tooling And Manual Overhead: Talent teams are forced to manually toggle between platforms like Skillex (Axelerant’s Internal staffing platform), Maven, Timetastic, and spreadsheets. The lack of integration leads to lost time, duplication of work, and frequent errors in availability assessments.
- Unstructured Job Descriptions: JDs are often written in free-form language, with varying degrees of detail, making it difficult for traditional systems to extract structured requirements and match them against talent pools.
- Delays And Talent Waste: The result is slower staffing cycles, underutilized high-potential employees, and the risk of overloading visible team members while leaving others underleveraged.
The Solution: An AI-Native Staffing Engine
Axelerant's Intelligent Staffing and Allocation System addresses these problems through a layered, modular architecture that combines:
- LLM-Powered Skill Extraction And Normalization: We use large language models to extract skills and experience from both job descriptions and candidate profiles, then map them to a standardized skill ontology. This ensures consistency and comparability across all data sources.
- Canonical Skills Dictionary: By creating a single, normalized list of representative skills, we can standardize inputs from varied documents. This helps bridge the linguistic gap between how roles are described and how experience is listed.
- Vector And Keyword Search Hybrid: Using ChromaDB, the system supports both semantic (vector) search for deeper context and keyword search for exact matches. This dual approach improves match precision and provides flexibility for different staffing use cases.
- Real-Time Availability Integration: We integrate with tools like Maven and Timetastic to ensure only currently available or soon-to-be-available candidates are shown in results. This real-time layer transforms candidate search into actionable staffing decisions.
- Future-Ready Design: The initial release is built as a synchronous API, but it is architected with async workflows in mind, ensuring it can evolve into a fully event-driven, scalable system.
How We’re Using AI And LLMs To Power Talent Matching
Our Intelligent Staffing and Allocation System leverages AI and LLMs in several tightly integrated, functional layers. These are not generic uses of AI; they are specifically designed and structured to resolve the fragmented nature of internal staffing.
1. Canonical Skill Extraction Using LLMs
We start by generating a representative, normalized list of skills, a canonical dictionary. This is created by passing a curated sample of real-world job descriptions and resumes to an LLM prompt, which extracts consistent and domain-specific keywords. This ensures uniform representation of skills across data sources.
2. Standardized Parsing For JDs And Candidate Profiles
When a JD is submitted, it is parsed by the LLM using a prompt that incorporates the canonical skill list. The LLM is instructed to extract and map relevant skills from the JD to this predefined list. Similarly, resumes and profiles from Skilex are also passed to the LLM with a similar canonical prompt, ensuring standardized extraction and tagging.
This alignment ensures that we can compare JDs and candidate profiles without falling into the trap of mismatched terminology (e.g., "ReactJS developer" vs. "Frontend engineer with JavaScript experience").
3. Embedding And Indexing
Once the LLM extracts the standardized skills and summaries, we embed the relevant data (skills + experience + description) into vector representations and store them in ChromaDB. Alongside the embeddings, we also store the LLM’s structured output to support hybrid search:
- Vector search for semantic similarity
- Keyword search for exact canonical matches
This dual-mode architecture gives us a highly tunable and transparent search capability.
4. Intelligent Candidate Matching
When a /similar_candidate API is invoked, the query JD undergoes the same LLM-based parsing and canonicalization. The system then:
- Retrieves relevant candidate embeddings using vector similarity
- Optionally applies keyword filtering via the stored canonical tags
- Returns results enriched with match scores, gaps, and metadata for transparency
This LLM-powered system design ensures accuracy, interpretability, and performance across various staffing scenarios.
5. Future-Proof Structuring
Even though the current implementation uses a synchronous API, the system is architected to evolve into an asynchronous pipeline. The prompt design, skill dictionary extraction, and data models have all been created with long-term adaptability in mind, supporting parallel processing, feedback loops, and batch ingestion at scale.
High-Level Architecture
|
Layer |
Functionality |
Tools |
|
JD Parsing |
Convert unstructured JDs into structured skill schemas |
LLM + LangChain |
|
Skill Normalization |
Align candidate and JD skills to a canonical list |
LLM + custom prompts |
|
Vector Indexing |
Store embeddings with metadata |
ChromaDB |
|
Search API |
Match JDs to candidates using vector + keyword search |
REST + ChromaDB |
|
Availability Filtering |
Integrate with Maven + Timetastic to remove unavailable profiles |
Custom logic + external APIs |
|
Scoring & Explanation |
Rank candidates and display matched/missing skills |
LLM + Internal scoring module |
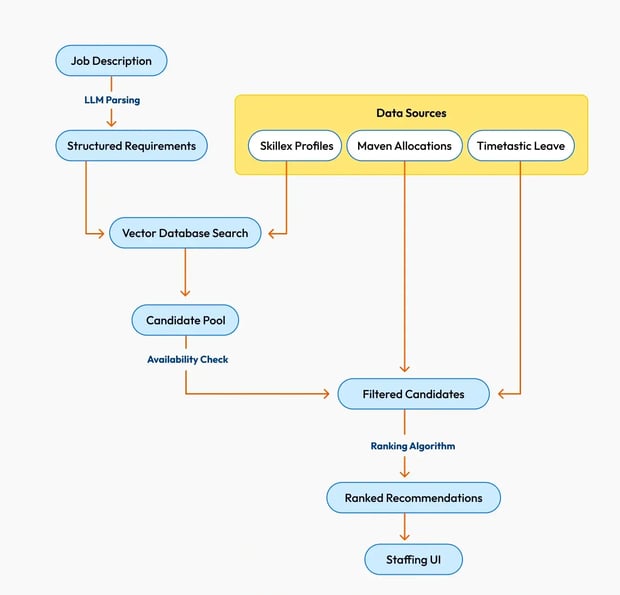
How It Works: From JD to Candidate Match
This system uses a systematic approach to match the right talent to the right project.
- JD Submission: A staffing lead submits a job description, either via API or future UI interface. This JD may include responsibilities, must-have and nice-to-have skills, seniority expectations, and timelines.
- LLM Parsing and Skill Mapping: The job description is processed through a prompt-engineered LLM workflow. It extracts core requirements and maps them to our canonical skill dictionary, ensuring consistency in how roles are defined across teams.
- Candidate Profiling and Indexing: Employee profiles, resumes, or Skillex data are similarly parsed and normalized. ChromaDB stores both the raw LLM output (for explainability) and the semantic embedding (for deep matching).
-
Search and Ranking Logic
- A semantic vector search is run to find contextually similar candidates, using cosine similarity.
-
- A keyword search is simultaneously performed to ensure mandatory skills are matched.
-
- Results are scored and filtered based on availability and capacity.
- Results are scored and filtered based on availability and capacity.
- Availability Integration: The system checks leave data and existing allocation schedules to ensure recommended candidates are realistically assignable.
- Result Presentation with Context: Matched candidates are returned along with metadata: why they matched, where gaps exist, and when they’re next available. This transparency aids quick decision-making and encourages confidence in recommendations.
Why This Matters: Engineering a Strategic Advantage
This system fundamentally shifts staffing from being reactive and fragmented to proactive and data-driven. Its business impact is tangible:
- Accelerated Staffing Turnaround: What used to take days of back-and-forth now becomes a query-driven process that can be completed in minutes.
- Better Role Fit And Performance: Semantic understanding ensures candidates are matched not just on buzzwords, but on meaningful experience and contextual relevance.
- Increased Employee Visibility And Utilization: By surfacing profiles beyond the usual suspects, the system helps unlock hidden talent and reduce underutilization.
- Improved Morale And Fairness: Transparent and explainable staffing decisions boost internal trust and reduce perceived bias.
- Scalable Operations: As team size increases, the system scales without additional overhead, freeing up staffing managers to focus on exceptions, not every case.
Engineering Staffing That Thinks Ahead
Too often, staffing is treated as a peripheral, back-office function, a logistical exercise handled through repetitive queries and personal networks. But in reality, it is one of the most influential levers an organization has for delivering value, maintaining agility, and improving employee satisfaction.
With this system, we aren’t just accelerating staffing workflows; we’re elevating how decisions are made about people. We’re creating a smarter, more equitable approach to matching talent with opportunity, where data and intent replace guesswork and visibility gaps.
At Axelerant, we believe that technology should not only support operations but also enhance the way people are empowered within them. Our Intelligent Staffing and Allocation System reflects that belief. It’s built on engineering rigor, powered by AI, and shaped by the realities of fast-growing, distributed teams.
If your organization is feeling the friction of inefficient staffing or the limits of manual resource planning, it might be time to rethink your approach. This is because smart staffing isn’t just a feature, it’s a foundation for what’s next.

Bassam Ismail, Director of Digital Engineering
Away from work, he likes cooking with his wife, reading comic strips, or playing around with programming languages for fun.




Leave us a comment