 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.Software users demand performance and seamless user experiences. 53% of the time, mobile site visitors leave a page that takes more than three seconds to load. When your application scales up, handling massive amounts of data becomes challenging.

Source: UserGuiding
Kafka is an excellent solution to handle huge volumes of data as its capabilities are as follows:
- Messages In Per Second: Up to 1 million
- Bytes In Per Second: Tens of gigabytes
- Latency: Typically under 10 milliseconds
- Replication Latency: Single-digit milliseconds
- Durability: Data replicated across 3 or more brokers (common replication factor is 3)
- Cluster Size: Scalable to hundreds of brokers
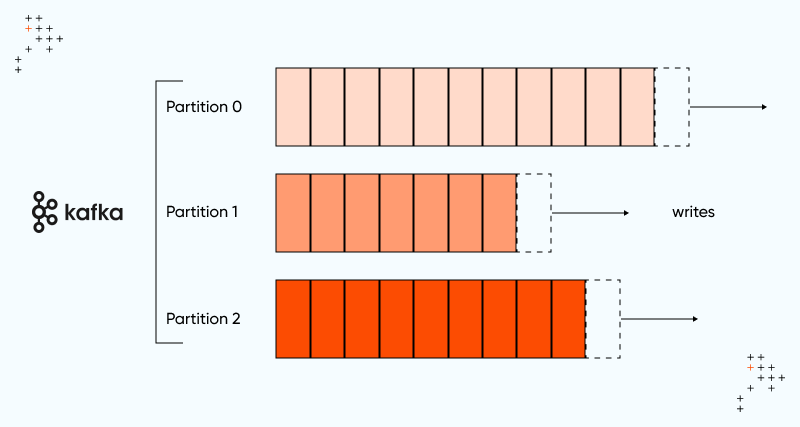
The key abstraction in Kafka is the topic. Kafka partitions are key to enhancing your application’s performance, enabling efficient data handling and improved scalability.

Source: Kafka
Understanding Kafka, Topics, And Partitions
Apache Kafka is an open-source distributed event streaming platform for building high-performance data pipelines, streaming analytics, data integration, and applications. Kafka facilitates a publisher-subscriber model and is useful for building a distributed and decoupled application.
The basis of Kafka is servers and clients. Kafka clusters are run on multiple servers across the globe, and they form the data storage layer, also known as brokers. If any of the servers go down, other servers take over the load, making Kafka highly scalable and fault-tolerant.
Kafka Clients facilitate writing distributed applications and microservices that read, write, and process streams of data as they occur or retrospectively. Clients are available for Java and Scala, including the higher-level Kafka Streams library, Go, Python, C/C++, and many other programming languages, as well as REST APIs.
Kafka Topics serve as the organizational categories for messages, each distinguished by a unique name across the entire Kafka Cluster. Messages are directed to and retrieved from specific topics, facilitating streamlined data management.
Kafka Partitions divide a single topic into several logs, each capable of residing on distinct nodes within the Kafka cluster. This partition facilitates distributing the tasks of message storage, composition of new messages, and processing existing messages across multiple nodes within the cluster.
A simple analogy would be: Imagine Kafka as a high-speed highway for data, where messages flow like cars on lanes. Each lane represents a partition, and each message is like a car traveling along its assigned lane. Kafka ensures efficient processing and scalability by splitting the data across multiple partitions.
Benefits Of Kafka Partitions
1. Parallel Processing: Partitions help your application process more messages concurrently, boosting overall performance. With multiple partitions, Kafka enables parallel message processing.
2. Scalability: You can increase the partitions depending on your app's requirements. This allows you to distribute the workload evenly. When you onboard more users and want to handle large data, Kafka partitions provide scalability without compromising performance. Thus, Kafka partitions ensure your application effortlessly handles increasing traffic.
3. Fault Tolerance: One feature that makes Kafka an interesting solution is its fault tolerance capabilities. Each partition maintains multiple replicas, ensuring that even if a broker (server) goes down, data remains accessible, and your application stays up and running without glitches.
4. Optimized Throughput: Kafka uses partitions to its advantage to optimize throughput. It strategically distributes data across partitions to increase output and reduce downtime. As a result, messages are processed efficiently, reducing latency and ensuring that your application delivers real-time experiences to users.
Tips To Improve Application Performance Using Kafka Partitions
1. Partition Design: When designing the partitions, it is important to identify the key attributes or characters of your data. The optimal partitioning strategy should be considered so that it can serve as natural partition keys. For example, if you’re processing user events, consider partitioning by user ID to ensure that related data is stored together.
2. Partition Count: Though there is no golden rule for partitioning, you can arrive at a number based on your app’s scalability requirements. Based on the expected workload and scalability requirements, determine the appropriate number of partitions for your topics. It is imperative to be mindful while partitioning, as too many partitions can lead to overhead and management complexities. On the other hand, more partitions offer increased parallelism. So, strike a balance to achieve optimal performance.
3. Consumer Scaling: When you don’t plan consumer scaling, it might result in bottlenecks. You have to scale your consumer applications horizontally to match the partition count. Each consumer group can have multiple instances, with each instance assigned to one or more partitions. As a result, you can utilize the available resources efficiently and avoid bottlenecks.
4. Monitoring and Optimization: Since partitioning is an ongoing process, and there is no rule of thumb to follow, you have to monitor certain metrics to ensure performance. For example, you have to monitor Kafka cluster metrics such as partition lag, throughput, and consumer lag to arrest performance bottlenecks and fine-tune your partitioning strategy. You can adjust or rebalance partitioning counts as required for your app’s performance.
Kafka Topic Partitioning Best Practices
Kafka handles vast streams of data effortlessly and reliably like no other tool. The topic partitioning mechanism helps Kafka stand out from the crowd, and it can either break or make your data pipeline. So here are some best practices for Kafka topic partitioning for seamless data processing.
1. Understanding Your Data Access Patterns
You should know the answers to some questions before making partitioning decisions. Is your application dealing with high-throughput, low-latency data streams, or is your data more sporadic? When you understand your data access patterns, you know how your data is produced and consumed. This helps in making informed decisions during crucial times.
2. Choosing An Appropriate Number Of Partitions
Kafka’s parallelism and throughput capabilities depend on the number of partitions. Having more partitions than required can overload the system, while less partitions may bottleneck your system. Understand your data volume, processing requirements, and scalability needs to find the right balance.
3. Utilizing Key-Based Partitioning When Necessary
Key-based partitioning is useful when order preservation or grouping of related data is essential. It also allows for deterministic routing of messages based on a defined key. You can maintain data integrity and streamline downstream processing by ensuring that messages with the same key always land in the same partition.
4. Considering Data Skew And Load Balancing
When certain keys or partitions receive disproportionate traffic, it results in data skew. This can degrade system performance and lead to uneven resource utilization. With the help of consistent hashing or dynamic partition balancing strategies, you can mitigate skew and ensure equitable distribution of workload across partitions.
5. Planning For Scalability
Scalability is one of Kafka’s prominent features, but achieving that takes a lot of planning while partitioning. It is recommended to consider future growth while designing your topic partitions. Also, you need to plan for increased data volumes, consumer groups, and processing requirements without necessitating disruptive reconfiguration.
6. Setting An Appropriate Replication Factor
During node failures, Kafka counters data loss and high availability using its replication capabilities. Formulate a replication factor that helps you strike a balance between resource utilization and fault tolerance, considering factors such as data criticality, durability requirements, and cluster size.
7. Avoiding Frequent Partition Changes
Though Kafka allows dynamic partition reassignment, frequent changes can interrupt data processing and pile up unnecessary overheads. It is imperative to ensure stability in partition assignments such that you revisit them only when a significant change in workload or cluster topology is observed.
8. Monitoring And Tuning As Needed
Since Kafka is also a distributed system, it benefits from monitoring and optimizing the partitioning strategy. Monitor key metrics such as partition lag, throughput, and resource utilization, and adjust partitioning strategies accordingly to maintain optimal performance.
Conclusion
Efficient data management is crucial for application performance. Apache Kafka’s partitioning mechanism enhances scalability, fault tolerance, and throughput. By designing optimal partitions, scaling consumer applications, and using key-based partitioning, you can improve parallel processing and workload distribution.
Meanwhile, adhering to best practices, such as planning for scalability and avoiding frequent partition changes, ensures high availability and performance. Regular monitoring and tuning of partitioning strategies allow your application to handle increasing traffic and deliver seamless user experiences, leveraging Kafka’s full potential.
Schedule a meeting with our experts to learn more about how Kafka Partitions can improve your app’s performance.

Qais Qadri, Senior Software Engineer
Qais enjoys exploring places, going on long drives, and hanging out with close ones. He likes to read books about life and self-improvement, as well as blogs about technology. He also likes to play around with code. Qais lives by the values of Gratitude, Patience, and Positivity.





Leave us a comment