 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.Here is a scenario most teams building with AI coding agents will recognize.
You configure an AI agent to work through a structured development workflow. Ticket intake, implementation planning, file generation, config cycles, linting, PR review, validation. Twelve steps, maybe more. Each step produces useful output. The agent handles step one well. Step five is solid. By step ten, something is off. The PR review is shallow. The validation step misses things a junior engineer would catch.
You rerun the workflow. Same result. The later steps are consistently weaker than the earlier ones.
This is not a model capability problem. It is a context pollution problem.
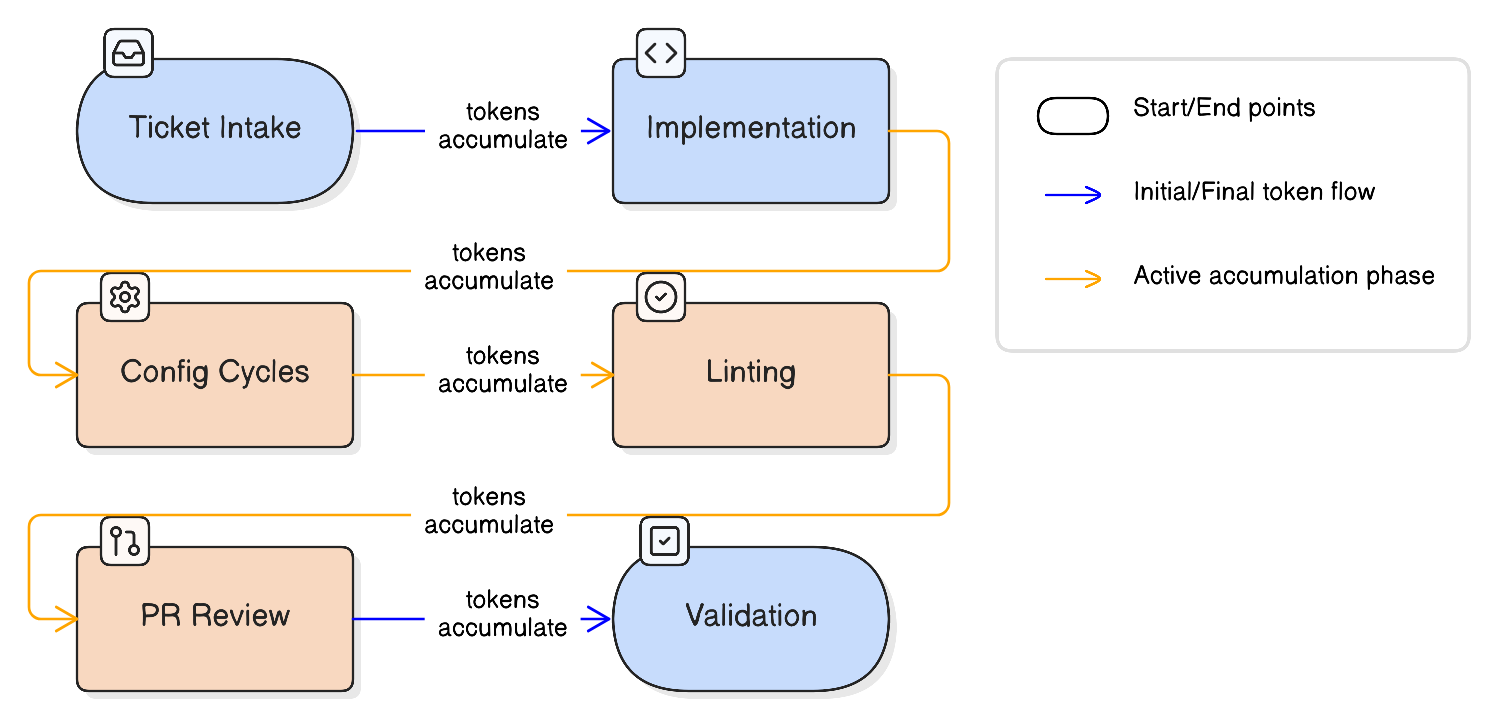
Our engineering team builds and maintains an internal SDLC plugin that orchestrates AI agents through a multi-step workflow for handling Jira tickets. The plugin manages the full lifecycle: from implementation through configuration, linting, and PR review. When running all 12 steps in a single context window, the conversation accumulated between 200,000 and 400,000 tokens. At that volume, the model was forced to compress earlier context to fit new information.
The compression is silent. No error. No warning. The model simply loses fidelity on the instructions and outputs it encountered earlier in the conversation. By the time it reaches PR review, the step where quality matters most, the model is working with a degraded version of its own earlier work.
How We Discovered The Degradation
The quality loss did not announce itself. It surfaced through a pattern that only became visible after running the full workflow end-to-end across multiple real tickets. PR reviews were vague where they should have been specific. Validation steps produced surface-level checks instead of the thorough analysis the same model delivered when running validation in a fresh context.
The telling experiment: run the same PR review step in isolation, with a clean context window, and the output quality jumped noticeably. The model was not incapable. It was starved of usable context.
This pointed directly at the architectural problem. Running 12 sequential steps in a single conversation treated the context window as an infinite resource. It is not.
The Hypothesis
If the primary quality degradation came from context compression in later workflow steps, then reducing the token load in the main conversation should restore output quality without changing any of the agent's behaviors or safety guardrails.
Two intervention paths emerged:
| Intervention | Mechanism | Expected Impact |
|---|---|---|
| Prompt deduplication | Extract repeated instruction patterns across skill files into shared references, reducing baseline prompt size | Moderate token reduction in every step |
| Sub-agent architecture | Offload the heaviest workflow phase (implementation) to a separate context, keeping the main conversation lean for review and validation | Large token reduction in later steps |
Both could be executed without altering any skill behavior. That constraint was non-negotiable. Every skill needed to work identically in orchestrated mode (full workflow) and standalone mode (individual invocation).
What We Built
Prompt Deduplication: Applying DRY Principles To AI Skill Architecture
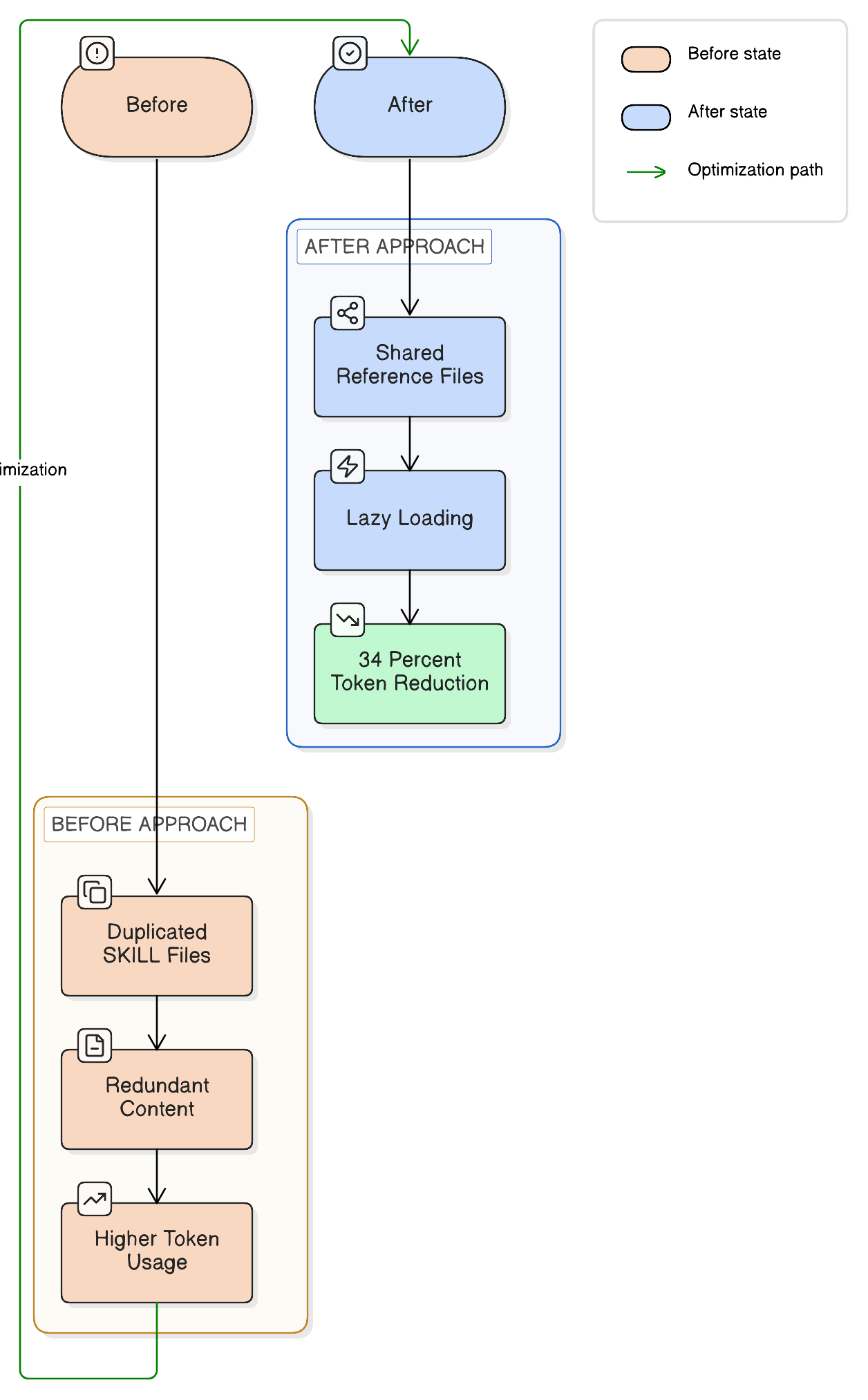
The SDLC plugin contained multiple skill files (SKILL.md) totaling 1,775 lines across all skills. Auditing these files revealed significant duplication: config workflow instructions, test workflow instructions, hard rules, Jira templates, and project environment descriptions appeared in multiple skill files, sometimes verbatim, sometimes with minor variations.
Prompt deduplication is the practice of extracting repeated instruction patterns from individual AI skill prompts into shared reference files that are loaded on demand, reducing total prompt size while preserving identical agent behavior.
We extracted these into 5 shared reference files:
| Shared Reference File | Content | Loading Strategy |
|---|---|---|
| Config workflow | Configuration import/export cycle instructions | On demand |
| Test workflow | Test execution and validation patterns | On demand |
| Hard rules | Safety guardrails and non-negotiable constraints | On demand |
| Jira templates | Ticket update and comment formatting | On demand |
| Project environment | Repository structure and tooling context | On demand |
The lazy loading strategy matters. Skills do not load all shared references at initialization. They pull only the references relevant to their current step. This keeps the token footprint proportional to what the agent actually needs at any given moment.
Result: Total SKILL.md lines dropped from 1,775 to 1,176. A 34% reduction (599 lines removed). Every safety guardrail, every hard rule, every functional behavior preserved. Nothing removed. Only deduplicated and condensed.
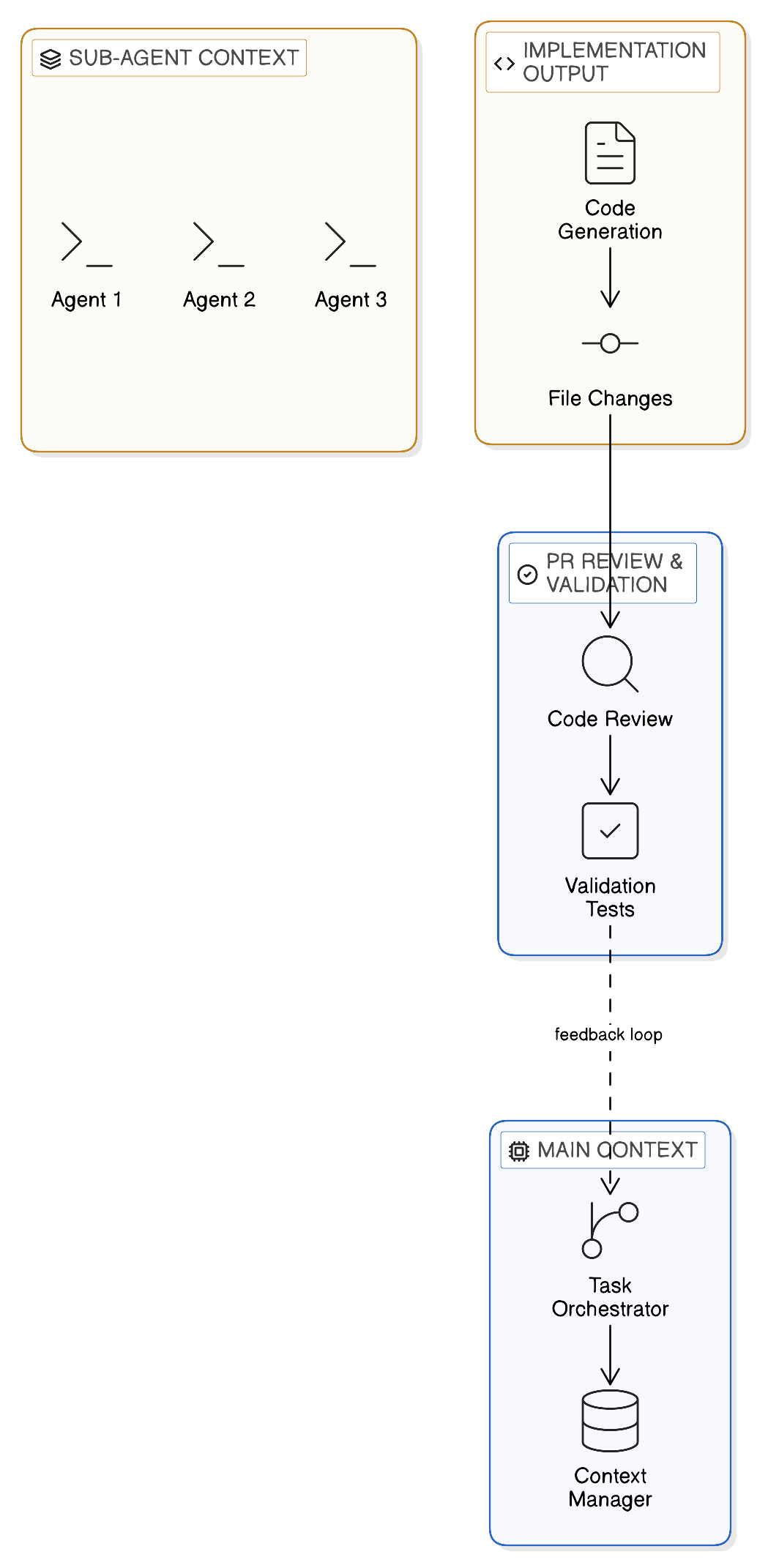
Sub-Agent Architecture: Splitting The Context Where It Matters
Deduplication alone was not enough. The implementation phase (file generation, config import/export cycles, lint fix iterations) is inherently token-heavy. It produces large volumes of code, configuration, and iterative correction output. This is the phase that pushes the context window past 200,000 tokens.
The architectural insight: the implementation phase is both the most token-heavy and the least needed in the main context for subsequent steps. PR review does not need to see every lint fix iteration. Validation does not need the full config import/export history. They need the final artifacts, not the journey.
We restructured the work-on-jira-ticket workflow to delegate the implementation phase to a sub-agent via the Agent tool. The sub-agent runs in its own context window, handles the heavy iteration work, and returns only the relevant outputs to the main conversation.
| Workflow Phase | Context | Token Profile |
|---|---|---|
| Ticket intake and planning | Main context | Light (~5–10K tokens) |
| Implementation, config cycles, lint iterations | Sub-agent context | Heavy (100–200K+ tokens) |
| PR review | Main context | Moderate (~20–30K tokens) |
| Validation and ticket update | Main context | Moderate (~15–25K tokens) |
This creates a natural architectural boundary. The main conversation stays lean. The sub-agent does the heavy lifting in isolation. PR review and validation run with full access to their context budget instead of fighting over scraps left after implementation consumed most of the window.
Projected result: Main context token usage drops to approximately 50,000 to 100,000 tokens. Down from 200,000 to 400,000. An estimated 75% reduction.
What We Know And What We Do Not Know Yet
Honesty about evidence strength matters more than inflated claims.
| Metric | Status | Confidence |
|---|---|---|
| Prompt line reduction: 1,775 → 1,176 (34%) | Measured | High |
| Main context token reduction to ~50–100K | Estimated, not yet validated with production metrics | Medium |
| 75% reduction in main context token usage | Estimated projection | Medium |
| Output quality improvement in PR review and validation steps | Observed anecdotally, not yet measured systematically | Low-Medium |
| Behavioral equivalence (all skills work identically) | Verified through testing | High |
The 75% token reduction figure is an architectural estimate based on which workflow phases move to the sub-agent context. We have not yet run a controlled before/after measurement across a statistically meaningful sample of tickets. That work is next.
What we can say with confidence: the architectural changes are deployed, behavioral equivalence is confirmed, and early usage indicates that late-stage outputs (PR reviews, validation) are qualitatively more thorough than before the change. Quantifying "more thorough" rigorously is a harder problem we have not yet solved.
The Transferable Pattern
This problem is not specific to our SDLC plugin. Any team running AI agents through multi-step workflows with more than a handful of sequential steps will hit context compression. The trigger point varies by model and by the token density of each step, but the pattern is universal.
Three principles generalize beyond our specific implementation:
1. Treat prompts as code. Apply DRY principles. Audit for duplication. Extract shared patterns. Version control your prompt files. The same engineering discipline you apply to application code applies to the instruction sets that govern your AI agents.
2. Identify the natural context boundaries in your workflow. Not every step needs to see every other step's full output. Find the phases where downstream steps need results but not process. Those are your sub-agent boundaries.
3. Measure context consumption, not just output quality. Token usage per workflow step should be an observable metric, not an afterthought. Context compression is silent. If you are not measuring token accumulation across steps, you will not know when you cross the degradation threshold until your outputs start getting worse.
The Broader Implication For AI-Assisted Development
Most organizations adopting AI coding agents treat the integration as a one-time setup. Configure the agent, connect it to the codebase, define the workflow, ship it. This misses a critical reality: AI tooling requires its own engineering discipline.
The SDLC plugin is not a static integration. It is a piece of infrastructure that requires architecture decisions, performance optimization, and ongoing iteration. Context window management is just one dimension. Prompt maintenance, skill versioning, guardrail evolution, and workflow decomposition are all ongoing engineering concerns.
Teams that treat AI agent deployment as "done" after initial setup will accumulate context pollution, prompt drift, and quality degradation over time. Teams that treat their AI tooling as a first-class engineering system will compound the productivity gains.
This is the second-order engineering problem in AI-assisted development. Building with AI is the first-order problem. Building the systems that make AI work reliably at scale is the second. Most of the industry is still on the first.
Frequently Asked Questions
What Is Context Pollution In AI Agent Workflows?
Context pollution occurs when an AI agent accumulates so many tokens across sequential workflow steps that the model compresses earlier context to fit new information. This compression silently degrades output quality in later steps, particularly affecting review and validation phases that depend on earlier context fidelity.
How Do You Know When Your AI Agent Is Hitting Context Limits?
The clearest signal is inconsistent quality between early and late workflow steps. Run your most quality-sensitive step (like PR review) both as part of the full workflow and in isolation with a fresh context. If the isolated version produces noticeably better output, context compression is likely the cause.
Can You Solve Context Pollution By Just Using A Model With A Larger Context Window?
Larger context windows delay the problem but do not eliminate it. A 200K token window still compresses when workflows generate 300K or 400K tokens of accumulated context. Architectural solutions like sub-agent decomposition and prompt deduplication address the root cause rather than relying on model providers to outpace token growth.
What Is A Sub-Agent Architecture For AI Workflows?
Sub-agent architecture delegates token-heavy workflow phases to separate AI agent contexts, keeping the main conversation lean. The sub-agent handles intensive work (like code generation and iterative fixes) independently and returns only final artifacts to the main context, preserving context budget for downstream quality-sensitive steps.
Does Prompt Deduplication Risk Changing AI Agent Behavior?
When done carefully, no. The key constraint is that deduplication extracts shared patterns into reference files without removing or altering any instructions. Lazy loading ensures each skill loads only the references it needs. Behavioral equivalence testing after deduplication confirms that agent outputs remain identical across all invocation modes.
Axelerant Editorial Team
The Axelerant Editorial Team collaborates to uncover valuable insights from within (and outside) the organization and bring them to our readers.

Leave us a comment