
 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.The pitch is always the same. An AI design tool generates a landing page in 90 seconds. The audience gasps. The demo ends. And then someone on your team tries it with an actual brand system, and the output ignores your type scale, misapplies your color tokens, and invents a button style that exists nowhere in your component library.
This is not a minor inconvenience. For agencies managing design output across multiple client brands, an AI tool that cannot maintain brand fidelity is not a productivity gain. It is a rework generator.
The question is no longer whether AI can generate design. It can. The question is whether AI can generate design that ships without a human rebuilding half of it to match the brand system. A new generation of capabilities is forcing that question into sharper focus, and agencies need a framework for evaluating what actually matters.
The Four Capability Threshold For Production AI Design
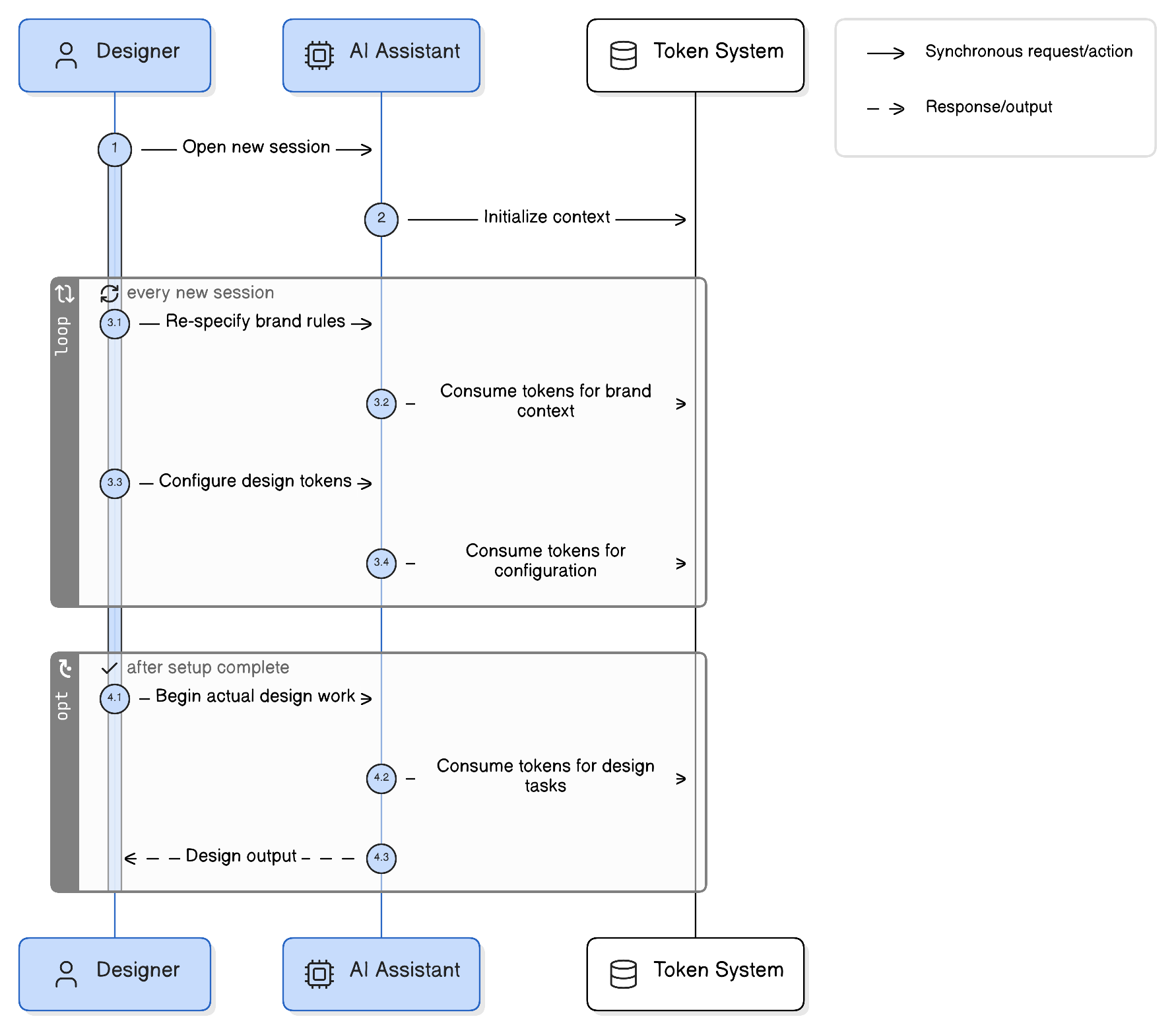
After tracking the evolution of AI design tooling across platforms like Figma AI, Vercel v0, Galileo, Uizard, and now Anthropic's Claude Design, a pattern emerges. The tools that cross from demo to daily driver share four capabilities. Missing any one of them creates a workflow bottleneck that erases the time savings.
The Four Capability Threshold is an evaluation framework for determining whether an AI design tool is production-ready for agency workflows. It assesses tools across Persistence, Manipulation, Integration, and Extensibility.
| Capability | What It Means | Why It Matters For Agencies | What "Good Enough" Looks Like |
|---|---|---|---|
| Persistence | Brand parameters carry across sessions and projects, not just within a single prompt | Agencies manage 5, 15, 50+ client brands. Re-specifying brand rules per session is unsustainable | Tool retains type scale, color tokens, spacing rules, and component patterns across projects without re-prompting |
| Manipulation | Users edit outputs directly on a canvas rather than regenerating from scratch | Designers need to adjust, not restart. Prompt-only iteration is too coarse for production refinement | Direct selection, repositioning, style overrides, and component swaps without returning to the prompt |
| Integration | Design outputs connect to code generation workflows natively | The design to code handoff remains one of the highest friction transitions in product development. AI that generates design and code from the same source eliminates an entire class of translation errors | Outputs produce usable code (not just images), with structure that maps to real component architectures |
| Extensibility | The tool connects to other tools in the design and development pipeline | No tool exists in isolation. If AI design output cannot flow into version control, project management, or asset management, it creates a new silo | API access, plugin architecture, or native integrations with at least 3 tools already in the agency's stack |
Most AI design tools available today deliver on one or two of these capabilities. Very few deliver on all four. The evaluation is not "which tool is best" but "which tool clears all four thresholds for your specific workflow. "
Why Persistence Is The Hardest Problem And The One That Matters Most
Of the four capabilities, persistence is the one most AI design tools fail on, and it is the one that matters most for agencies.
Consider the operational reality. An agency with 20 active client engagements runs design work across 20 distinct brand systems. Each brand system includes (at minimum) a primary and secondary type scale, a color palette with semantic tokens, spacing and grid rules, component variants, and tone of voice guidelines. If an AI design tool requires the designer to re-specify these parameters at the start of each session, the time savings from AI generation gets consumed by setup overhead.
The exact cost depends on how complex the brand system is and how many sessions a designer runs per week. But the direction is clear: without persistence, every session starts with a configuration tax. The more clients you manage, the higher that tax scales. With full persistence, that tax drops to zero. The gap between those two states is where the real ROI question lives for multi-brand agencies.
Anthropic's Claude Design update specifically addresses this with persistent brand system adherence across projects. This is notable because it moves the tool from the "impressive demo" category into the "potentially production-viable" category for multi-brand agency work. But the claim needs validation in practice. Persistent brand adherence in a controlled demo and persistent brand adherence across weeks of real project work with evolving brand guidelines are very different things. No independent production validation at agency scale is publicly documented yet.
The Design To Code Gap Is A Brand Fidelity Problem, Not A Handoff Problem
The conventional framing of the design to code gap focuses on the handoff: the moment when a designer passes specifications to an engineer, and the engineer interprets them. Tooling improvements in this space (Figma Dev Mode, Zeplin, design tokens) have reduced friction but not eliminated it.
The deeper problem is brand fidelity degradation across the pipeline. Every transition point between tools introduces drift.
| Pipeline Stage | Where Drift Happens | Typical Manifestation |
|---|---|---|
| Design concept to component spec | Designer interprets brand system; AI tool interprets prompt | Color values approximated, type sizes rounded, spacing inconsistent |
| Component spec to code | Engineer interprets spec; framework constraints override design intent | CSS overrides, framework defaults persist, responsive breakpoints shift layout |
| Code to deployed output | Build tools, CDNs, and browser rendering introduce variation | Font loading delays, image compression artifacts, platform-specific rendering |
| Deployed output to next iteration | Feedback references deployed version, not source design | Drift compounds as each iteration references a degraded version |
AI tools that integrate design generation with code generation (Claude Design's Claude Code integration, Vercel's v0) attack this problem by collapsing the first two transition points. If the same system generates both the visual design and the code, one class of translation error disappears entirely.
This is not a theoretical advantage. For agencies billing on project delivery timelines, eliminating even one round of "the build does not match the design" rework per project translates to measurable margin recovery. The specific magnitude will vary by team, project complexity, and brand system rigor, but any agency that tracks rework hours already knows this is a meaningful line item.
An Evaluation Framework For Agencies Considering AI Design Tooling
Before any agency evaluates a specific tool, they need to evaluate their own readiness. The following framework maps the decision.
Stage 1: Workflow Audit
Answer three questions before looking at any tool:
- Where does brand fidelity degrade in your current pipeline? Map every transition point. Identify the top 3 by rework frequency.
- What percentage of design time is spent on production work vs. creative exploration? AI tools accelerate production (variations, responsive layouts, component generation) more than exploration. If the majority of your design hours are production, the ROI case is stronger.
- How formalized are your client brand systems? AI tools that promise brand adherence need structured inputs. If your brand systems live in a designer's head rather than in documented tokens and specs, no tool can persist what is not defined.
Stage 2: Capability Threshold Assessment
Evaluate candidate tools against the four thresholds. Score each on a 1 to 5 scale:
| Tool | Persistence (1, 5) | Manipulation (1, 5) | Integration (1, 5) | Extensibility (1, 5) | Total |
|---|---|---|---|---|---|
| Tool A | ? | ? | ? | ? | /20 |
| Tool B | ? | ? | ? | ? | /20 |
| Tool C | ? | ? | ? | ? | /20 |
The scoring here is necessarily subjective and context-dependent. What matters is the pattern: a tool scoring well in three categories but poorly in one will create a bottleneck that negates the strengths. Balance matters more than peaks. Your team should define what a 3, 4, or 5 looks like for each capability based on your specific workflow before scoring.
Stage 3: Pilot Design
Structure a time-boxed pilot (two weeks is a reasonable starting point) with these constraints:
- Use one real client project, not a hypothetical exercise
- Use the client's actual brand system, not a simplified version
- Measure three things: time to first production-ready output, number of brand fidelity corrections required, and designer satisfaction (would they use it again unprompted? )
- Have two designers run the same brief: one with the AI tool, one without. Compare outputs on fidelity, not just speed
The pass/fail threshold will depend on your team's tolerance for corrections. The key question is whether the AI-assisted output requires meaningfully fewer manual fixes than your current process, or whether it simply trades one type of rework for another. If designers are spending more time correcting AI output than they would have spent creating it manually, the tool is not production-ready for your context regardless of its generation speed.
What This Means For Agencies Right Now
The AI design tooling landscape is crossing a threshold. The first generation of tools proved AI could generate design. The current generation is proving (or failing to prove) that AI can generate design within the constraints that agencies actually operate under.
Three implications for agency leaders:
Your brand system documentation is now infrastructure. It was always important. Now it is the input layer for AI tooling. Agencies with well-documented, token-based brand systems will adopt AI design tools faster and more effectively. Agencies with informal brand knowledge locked in senior designers' heads will struggle regardless of which tool they choose.
The design to code boundary is dissolving. Tools like Claude Design with code integration and Vercel v0 are collapsing a pipeline stage that has existed for decades. Agencies that still organize teams around a hard design/engineering boundary will need to rethink structure as this capability matures.
Evaluation discipline matters more than tool selection. The market is moving fast enough that any specific tool recommendation has a short shelf life. The evaluation framework (audit, threshold assessment, pilot) is the durable asset. Build the muscle to evaluate rapidly, pilot cheaply, and adopt or discard based on measured results rather than demo impressions.
Frequently Asked Questions
Can AI Design Tools Actually Maintain Brand Consistency Across Projects?
The newest generation of tools, including Claude Design, claims persistent brand system adherence across sessions and projects. This means brand parameters like color tokens, typography scales, and spacing rules carry forward without re-prompting. However, production validation across extended timelines and complex brand systems remains limited. Agencies should pilot with real brand systems before trusting persistence claims at scale.
How Does The Design To Code Integration Actually Work In Practice?
Tools like Claude Design with Claude Code integration generate both visual design and corresponding code from the same source, eliminating translation errors between designer and engineer. The output maps to component architectures rather than producing flat images. This collapses one full pipeline stage, but code quality and framework compatibility vary significantly. Agencies should evaluate whether generated code meets their specific tech stack requirements during a structured pilot.
What Should Agencies Do Before Adopting Any AI Design Tool?
Agencies should complete a workflow audit before evaluating any tool. This means mapping every point where brand fidelity degrades, calculating the ratio of production to creative design work, and assessing how well brand systems are documented in structured formats like design tokens. Without formalized brand system inputs, no AI tool can deliver on its persistence and consistency promises.
How Do You Compare AI Design Tools Against Each Other?
Use the Four Capability Threshold framework: score each tool on Persistence, Manipulation, Integration, and Extensibility using a 1 to 5 scale. Define what each score means for your specific workflow before evaluating. A tool excelling in three areas but failing in one creates bottlenecks that negate its strengths. Run a time-boxed pilot on a real client project measuring time to production output, brand corrections needed, and designer willingness to reuse.
Is Claude Design Ready For Agency Production Work?
Claude Design's announced capabilities, including persistent brand systems, canvas editing, code integration, and expanded tool connections, address all four evaluation criteria at the feature level. No independent production validation at agency scale is publicly documented yet. The responsible path is a structured pilot with a real brand system, measuring correction frequency against a manual baseline before committing to broader adoption.
Axelerant Editorial Team
The Axelerant Editorial Team collaborates to uncover valuable insights from within (and outside) the organization and bring them to our readers.

Leave us a comment