
 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.The bug count was climbing. Not dramatically, not all at once, but steadily. Regressions that should have been caught. Data edge cases no one wrote assertions for. Integration mismatches between services that only surfaced in staging. The kind of problems that make a team start doubting its own velocity, because every two steps forward come with one step back.
The project was a composable commerce build: a NextJS frontend, a headless CMS for content, and a commerce backend handling products, customers, and checkout. Three repositories. Multiple teams. A lot of moving parts. And not nearly enough automated tests to keep them honest.
The Gap Was Wider Than Anyone Realised
The QA team had done real work. They had built Playwright E2E tests covering authentication flows: registration with field validation, login with credential checks, forgot password with confirmation verification. They had a GraphQL API test that validated the customer creation pipeline, ensuring the hbm_id assigned during creation matched the one returned on query. These were solid, well-structured tests with environment-based execution, Loom walkthroughs, and documented execution steps.
But that was the extent of it. The frontend codebase had no unit tests. The CMS had no unit tests. The commerce backend had no unit tests. No integration tests across any of them. The Playwright suite covered what the QA engineer could see in a browser, but the business logic underneath, the API contracts between services, the error handling paths that only fire when something unexpected happens, none of that was covered.
We pulled up the repositories and looked at what was actually there versus what the codebase needed. The documentation said one thing. The test directory told a different story. Features were shipping, but the safety net underneath them had holes large enough for entire workflows to fall through.
The team was not being negligent. They were busy building. Testing had become a separate phase, something that happened after features were done, and the backlog of "things to test" was growing faster than the capacity to test them.

One Session, Three Codebases, Comprehensive Coverage
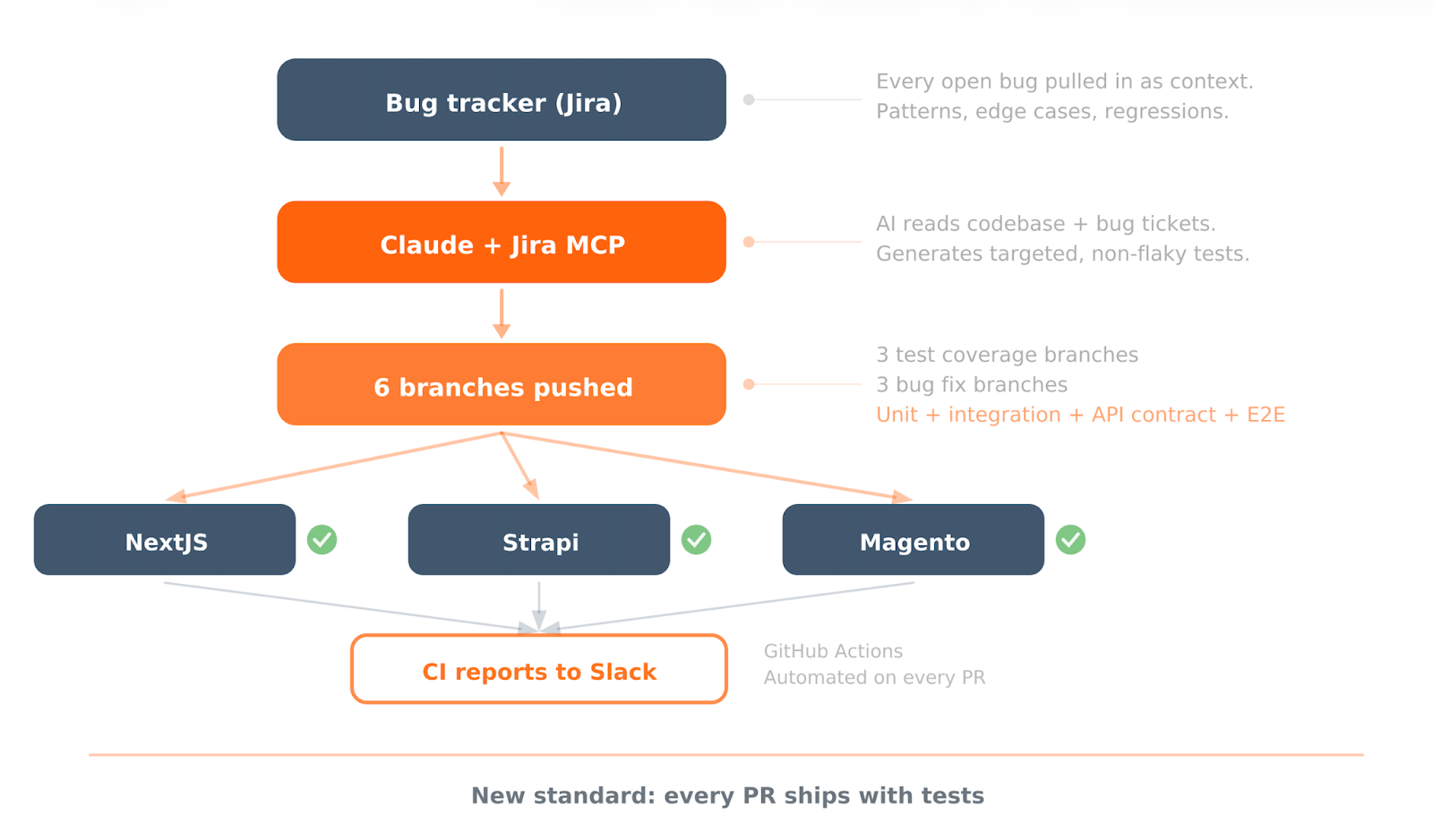
Instead of scheduling more QA sprints, instead of writing a testing strategy document, instead of having a meeting about having a meeting, he sat down with Claude, connected it to Jira via MCP, pointed it at every open bug in the project, and started generating tests.
Not placeholder tests. Not "it renders without crashing" assertions. Comprehensive test suites covering unit tests for business logic, API contract validation between services, error handling for edge cases, and integration checks across the stack. Across all three codebases. NextJS. Strapi. Magento.
The approach worked because of context. The AI had access to the actual bug tickets, so it knew exactly where the codebase was failing. It could see the patterns: which types of errors kept recurring, which integration points were fragile, which validation logic was missing. The tests it generated were targeted at the real weaknesses, not generated from a generic template.
He pushed six branches that same day. Three with comprehensive test coverage, three with fixes for open bugs. Each repository got both.
It was not entirely smooth. The generated tests needed verification. Some bug fixes could only be confirmed on one environment but not another, because the data conditions differed between dev and UAT. The frontend lead was able to verify one fix immediately but had to set the others aside for separate validation. This is the part that gets glossed over in AI stories: the output is fast, but the verification still requires someone who understands the system. The AI closed the gap in writing tests. A human still had to confirm they tested the right things.
The Team's Response Made It Stick
Within 48 hours, the frontend lead had merged both NextJS branches, verified what he could, and started running the new test suite in CI. The backend and CMS leads followed, merging the Strapi and Magento branches over the weekend.
But the important part was not the merge. It was what happened next.
The frontend lead looked at the test branches and said he would be deriving skills from these tests, building reusable patterns so that every new feature or modification would automatically get test coverage. That was the cultural shift. Not "we should write more tests" as a vague aspiration, but a concrete mechanism for making it happen by default.
The team updated their Confluence documentation into a proper test automation guide: directory structure, environment setup, tag-based test execution, CI configuration with GitHub reporters, retry logic, and parallel execution settings. What had been scattered notes became an operational standard.
The directive going forward was simple: every PR ships with tests. The code is already being written with AI assistance. The tests should be too. There is no reason for them to be separate.
What Actually Changed
The project went from having Playwright E2E coverage for authentication flows and a single API test to having unit tests, integration tests, and error handling coverage across all three platforms.
The test directory structure grew from a handful of spec files to a comprehensive suite covering auth flows, header and footer rendering, kitchen listing and detail pages, product listing and detail pages, smoke tests, and API contract validation.
More importantly, the team stopped treating testing as a phase. It became part of the development cycle. New features started arriving with tests attached. The QA engineer, who had been building Playwright coverage incrementally, now had a reference standard for depth and could focus on expanding coverage from a much stronger baseline.
The bug count did not drop to zero. That is not how software works. But the types of bugs changed. Fewer regressions. Fewer "this used to work" surprises. The problems that remained were genuinely new problems, not reruns of issues that better test coverage would have prevented.

What You Can Take From This
Here is a diagnostic we use now. If your team's bug backlog is growing, ask one question: are these new bugs, or are they bugs you have seen before wearing different clothes? If the answer is the second, your problem is not QA capacity. It is feedback loops. You are spending human effort catching things that automated checks should catch, and every cycle of that drains both velocity and morale.
AI-generated tests work best when they have context, not just code. Pointing an AI at a codebase and saying "write tests" produces generic coverage. Pointing it at a codebase plus every open bug ticket produces targeted coverage. The bug tracker is the most underused input in AI-assisted development. It contains the patterns your team keeps tripping over. Use it.
But the real lesson from this engagement is not about AI. It is about who sets the standard. The team saw what "good" looks like, merged it, and started building on it. A test suite that a team inherits gets scrutinised. A test suite that a leader demonstrates and the team then co-owns gets adopted. The difference matters.
If your composable commerce stack, or any multi-repo project, is accumulating bugs faster than your QA capacity can absorb, the bottleneck probably is not effort. It is approach.
We would be glad to think through your testing strategy with you. Talk to us.

Bassam Ismail, Director of Digital Engineering
Away from work, he likes cooking with his wife, reading comic strips, or playing around with programming languages for fun.

Leave us a comment