 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.
Most organisations are still treating AI as a productivity tool. We started treating it as internal product. Here's what that decision looked like in practice.
There is a gap in almost every organisation navigating an AI transition that nobody talks about directly.
On one side: a handful of people who have figured out how to use AI well. Their prompts are sharp. Their output is faster. They have found workflows that work for them and they use them consistently.
On the other side: everyone else. Same tool access. Meaningfully different results. And a growing sense that the gap between the two groups is not closing on its own.
The reason is structural. When AI capability lives in individual conversations and individual habits, it is inherently high-variance. The quality of the output depends entirely on the skill of the person asking. Knowledge does not transfer. Workflows do not replicate. What the best person figured out on Tuesday does not help anyone else on Wednesday.
The shift we made was simple to describe and harder to execute: we stopped treating AI as a productivity tool and started treating it as internal product. Something to be designed, versioned, and distributed — the same way we would treat any other piece of software the organisation depends on.
The result was a Claude plugin marketplace, accessible to every person in the company. Two plugins live. More in progress.
Here is what we built, how it works, and what we learned doing it.
The Problem With AI as Individual Productivity
Before we built the marketplace, our AI usage looked like most organisations' AI usage: distributed, uneven, and dependent on individual initiative.
Some team members had built sophisticated prompting habits. They knew how to structure a market research request to get useful output. They knew which framing produced better content. They had, through trial and error, developed a working knowledge of how to get reliable results.
That knowledge existed entirely in their heads. It did not live anywhere that other people could access, learn from, or build on. When a new person joined the revenue team or the content function, they started from scratch — going through the same trial and error, making the same calibration mistakes, arriving eventually at their own individual practice.
This is the hidden cost of treating AI as personal productivity. The organisation never accumulates. Every person is an island. The compounding that should be happening — where each person's discovery makes the next person better — simply does not occur.
Plugins are the structural answer to this problem. They move knowledge from individual heads into shared systems. They make the best practice the default practice. And they make that practice accessible to everyone — including the team members who would never have arrived there through individual experimentation.
"We stopped asking how we could help our people use AI better. We started asking what we could build so that good AI practice was automatic."
Plugin 1: The Revenue Plugin
The first plugin we shipped addresses one of the most consistent friction points in B2B GTM work: market intelligence.
Before a deal conversation, before a proposal, before a go/no-go decision — there is always a research phase. What is the total addressable market for this opportunity? Who are the real competitors? Is this segment worth pursuing? Getting rigorous answers to these questions used to take hours — if it happened at all. Under time pressure, it often did not. Teams went into conversations under-informed, or made decisions based on instinct when data was available but inaccessible.
The Revenue Plugin changes the economics of that research phase. A single command — /research-market — triggers a structured market intelligence workflow. The output covers total addressable market sizing, serviceable addressable market, competitive landscape analysis, and a go/no-go recommendation. Structured, consistent, shareable. In minutes, not hours.
The important distinction: this is not AI augmenting one person's research skills. It is AI making investor-grade market intelligence available to every revenue team member, on demand, regardless of their individual research capability. The quality floor for every deal conversation goes up.
Plugin 2: The Content Engine
The second plugin is more architecturally complex. It treats content production as a system — not a series of individual creative acts — and automates the workflow that connects raw signal to published content.
Nine specialised agents. Four integrations. Four commands. Here is how it works.
The pipeline begins with signal mining:
/mine-engagement Reads across connected data sources — HubSpot engagement records, Granola meeting transcripts, Slack channel activity, Google Drive documents — and surfaces the moments worth writing about. Client insights that revealed something. Delivery experiences that proved a principle. Internal conversations that captured an idea before it disappeared. The agent identifies what has content potential and surfaces it as a brief.
From signal to draft:
/create-content Takes a signal brief and produces a long-form blog post: researched, structured, written in brand voice, built to editorial standards. Not a first draft that needs to be rewritten from scratch. A draft that needs editing — which is a fundamentally different starting point. The agent writes against the brand identity, ICP framework, and tone of voice encoded in the knowledge layer.
From draft to distribution:
/distribute-content Adapts a published piece for specific channels. A blog becomes a LinkedIn post. A LinkedIn post becomes a platform-specific content update. A case study becomes a capability summary for a proposal deck. The agent knows the format requirements, audience expectations, and tone variations for each channel — because those are encoded in the knowledge layer, not regenerated from scratch each time.
Beyond individual pieces:
/create-content-pack Generates coordinated content programmes at the platform or industry level. Not one post — a structured series of posts, built around a specific technology platform (Drupal, HubSpot, Salesforce) or industry vertical. Each piece in the pack reinforces the others. The brand voice and positioning are consistent throughout. This is the command that turns content from a series of individual outputs into a programme.
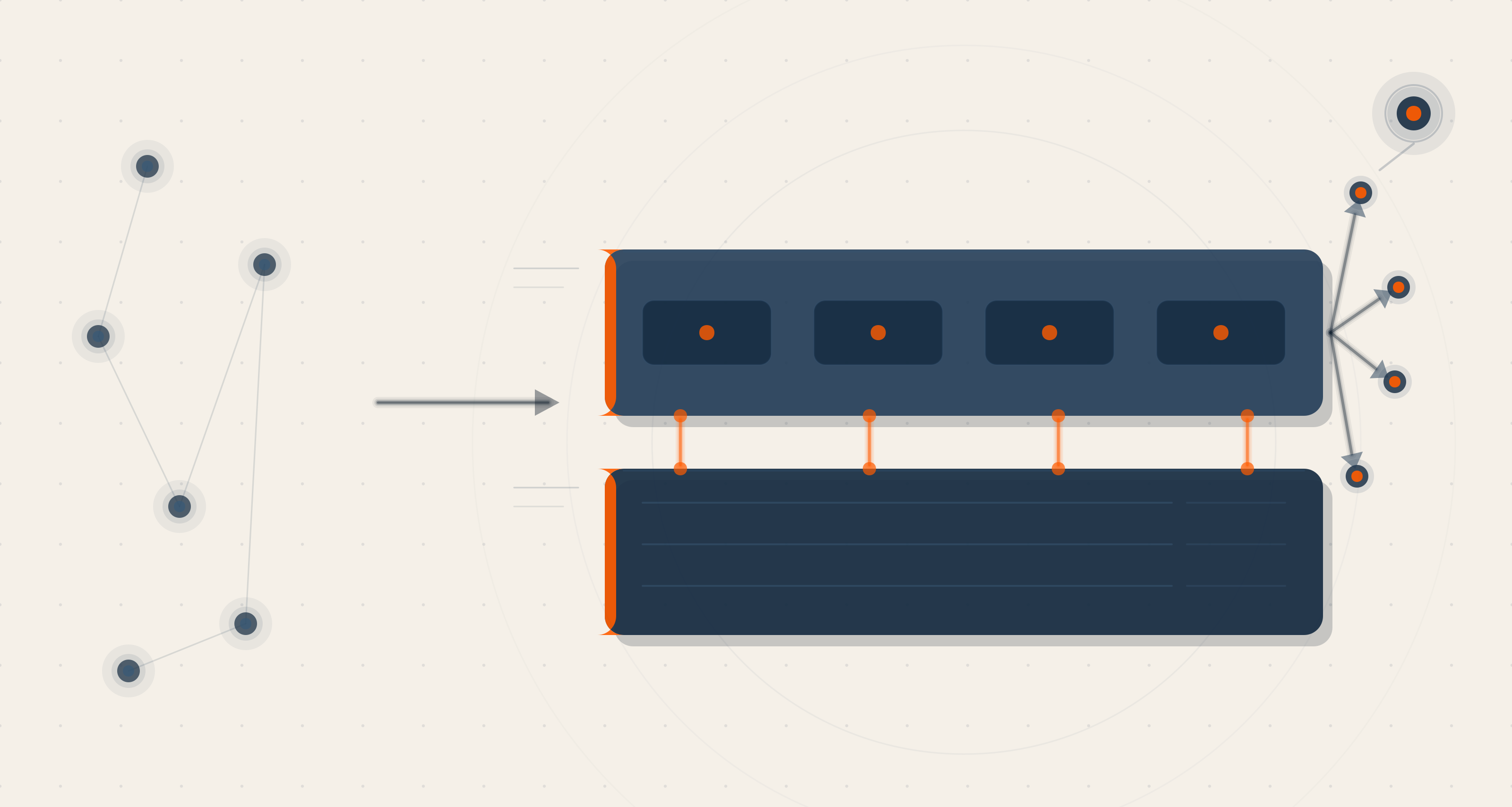
The Architecture That Makes It Work: Two Layers
The most important decision we made in building the Content Engine was not about the agents. It was about the separation between what the agents know and what the agents do.
Every AI system that depends on consistent, brand-aligned output needs to solve the same problem: how do you ensure the output reflects who you are, not just what you asked for? The naive answer is to include all that context in every prompt. The problem with that answer is that it is fragile, high-maintenance, and inconsistent. Context injected into prompts changes every time someone changes a prompt. There is no single source of truth.
Our answer was a two-layer architecture:
Layer 1 — Skills (the knowledge layer): Brand identity, tone of voice, ICP definition, buyer journey maps, service descriptions, competitive positioning. The things that should be consistent across every piece of output. These live as structured knowledge files — updated in one place, applied everywhere. When the brand positioning evolves, you update the skill file. Every agent that depends on that file gets the update automatically.
Layer 2 — Agents (the workflow layer): The nine agents that execute specific tasks — mine signals, write posts, adapt for channels, build packs. They draw on the knowledge layer for context, but they do not own it. Their job is to run the workflow reliably. The knowledge layer's job is to ensure the output is correct.
The practical implication of this separation is significant. The knowledge can evolve without breaking the workflow. The workflow can be updated or replaced without losing the knowledge. And non-technical team members — editors, strategists, brand managers — can update the knowledge layer directly in their browser, without needing to understand how the agents work.
That last point was deliberate and important. If updating the brand voice required filing a technical request, it would not happen consistently. Making it a browser-based edit — accessible to the people who own the brand, not the people who built the plugin — was the decision that made the system maintainable.
"The knowledge layer and the workflow layer are separate by design. The people who own the brand update the knowledge. The agents do the work."
Three Things We Learned Building This
Start with the workflow, not the technology. The plugins are useful because they map to real things people do every day — research a market, write a blog, prepare for a client meeting. We did not build AI features and then search for use cases. We mapped the existing workflows first — the ones that were already happening but slowly, inconsistently, and depending on whoever was available — and then designed AI to run them.
Consistency is more valuable than peak quality. Individual AI prompting is high-variance. Some outputs are excellent. Some are not. A plugin is low-variance — the structure, the knowledge context, the workflow steps are fixed. The output of a /create-content call on Monday morning and Friday afternoon should be structurally identical. That predictability is what makes it safe to depend on. It is what makes it a system rather than a tool.
The bottleneck shifts to context quality. Once the workflow is reliable, the variable is the quality of the knowledge you feed it. Weak brand documentation produces brand-inconsistent output. An incomplete ICP framework produces poorly targeted content. The plugin does not fix poor strategy — it runs it, faithfully and at scale. This is the forcing function that actually improves the underlying strategy work: when bad inputs produce bad outputs consistently, at speed, the pressure to fix the inputs becomes real.
What Comes After Version One
The Revenue and Content plugins are the first layer of what we are building. They automate the most repeatable, highest-frequency tasks in our GTM motion. The knowledge layer that powers them is now a maintained, versioned asset — not a set of prompts living in someone's notes.
The next layer is the one we are most interested in: applying the same infrastructure to client-facing work. Not just internal GTM, but delivery intelligence, client reporting, engagement health monitoring, and proposal generation. The same two-layer model. The same principle: knowledge in one place, workflows drawing from it.
AI-native delivery does not just mean faster internal operations. It means the entire engagement experience — from the first market research conversation to the final delivery review — runs on the same underlying intelligence layer.
That is what we are building toward. The marketplace is where it starts.

Brahmpreet Singh, Senior Marketing Manager
Brahmpreet Singh is a marketing professional with over a decade of experience in SaaS and B2B content strategy. He enjoys blending research-driven insights with creative storytelling to support meaningful growth in organic traffic and lead generation. Brahmpreet is dedicated to building thoughtful, data-informed marketing strategies that resonate with audiences and drive long-term success.


Leave us a comment