 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.When every system holds a different version of the same customer, personalization is impossible — not limited, not suboptimal, but genuinely impossible. Here's what that looks like in practice, and what it actually takes to fix it.
The Discovery That Changed the Scope
During a pre-sales discovery engagement with a global sports and lifestyle brand, a seemingly straightforward question — "how do you identify your customers across systems?" — produced an answer that reshaped the entire implementation plan.
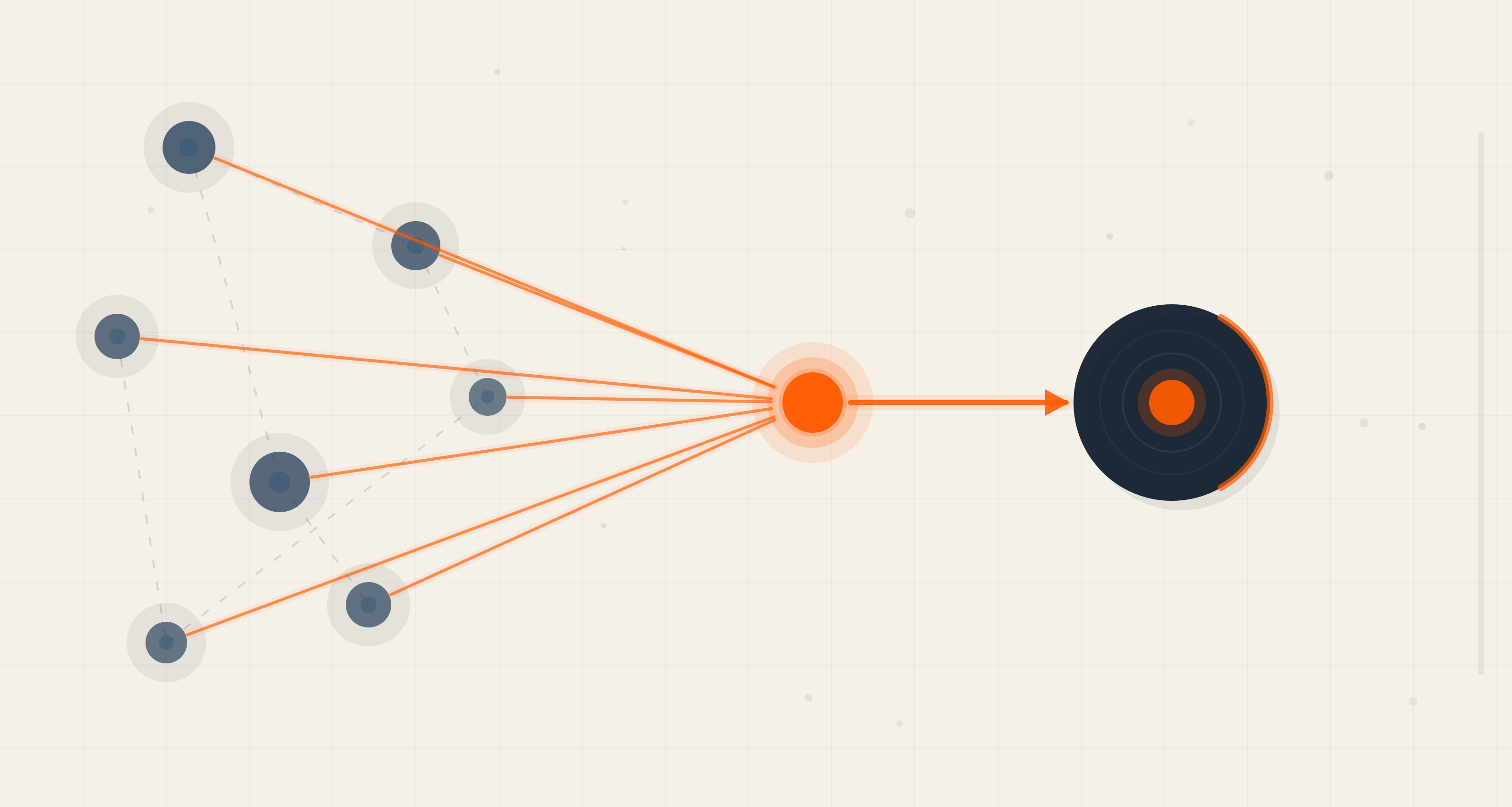
The client had Salesforce CRM. They had a Marketing Cloud. They had an LMS for online courses. They had a commerce platform, a membership club system, a mobile app, and an AWS data lake. And in each of these systems, the same person existed as a completely different entity.
A customer who had purchased a course, joined the membership club, booked travel, and downloaded the mobile app might exist as: a CRM contact, an LMS learner with a separate ID, a commerce transaction record, a club membership record with yet another identifier, a mobile app device ID, and an email subscriber in Marketing Cloud — all with no linking logic between them.
The practical consequence was damning. Teams couldn't connect what a customer had done across systems into a single journey. Marketing was sending campaigns based on partial profiles. The membership team had no visibility into whether a customer had recently purchased. The commerce team had no view of engagement history. Every team was making decisions from a fragment of the picture, not the whole.
The result: teams couldn't connect customer behaviors across systems into one journey.
That's not a tooling gap. That's an identity architecture gap. And it's the problem that a Customer Data Platform — specifically Salesforce Data Cloud — is designed to solve.
What Identity Fragmentation Actually Looks Like
It's worth being precise about what identity fragmentation means technically, because the business consequences are easy to describe but the architectural cause is often misunderstood.
Most enterprise systems are designed to be authoritative about their own domain. The CRM owns sales interactions. The LMS owns learning progress. The commerce platform owns transactions. Each system assigns its own identifiers — account IDs, member numbers, email addresses, device IDs, booking references — and those identifiers are not designed to cross-reference each other.
Over time, the same physical customer accumulates multiple identifiers across multiple systems. Some are linked by email address, but email addresses change. Some are linked by name, but names have variations. Some have no link at all — the LMS user created their account with a different email than the one in the CRM, and there's no shared key.
In this client's case: customer data was scattered across Salesforce CRM, Marketing Cloud, the eLearning platform, the membership club, travel systems, the commerce platform, and mobile apps — with no unified customer view. Duplicate and inconsistent records existed across systems, with the same user potentially appearing under multiple emails or profiles. And there was no real identity resolution between anonymous and known users.
The AWS data lake — which the client had invested in as their analytics backbone — was operating as a reporting repository, not an activation engine. It could tell you what had happened in aggregate. It couldn't tell you what this specific person had done across all their touchpoints, in a form that Marketing Cloud or the CRM could act on.
Manual deduplication and list management were increasing operational effort and error rates. Teams were spending time managing a problem that shouldn't have been a manual problem at all.
Why This Is an Architecture Problem, Not a Data Quality Problem
The instinct, when confronted with duplicate records and fragmented profiles, is to treat it as a data quality issue — clean up the duplicates, standardize the fields, enforce better data entry. That's the wrong frame.
Data quality problems are problems of inaccuracy within a system. What this client had was a structural problem across systems: the absence of an identity resolution layer that could probabilistically and deterministically link records from disparate sources into a single profile.
Deterministic matching works on exact keys: same email, same member ID, same phone number. Probabilistic matching works on weighted similarity: same name, same postal code, same purchase pattern — confident enough to merge, not certain enough to treat as identical.
The discovery process identified the priority identifiers for resolution: email, member ID, app login, certification ID, and payment card hash. And the governance question — who owns identity resolution policies — had never been answered.
A CDPimplements both matching strategies, maintains a merged profile, and then makes that profile available to downstream systems in real time. The CRM sees the unified view. Marketing Cloud targets unified segments. The commerce platform can personalize based on cross-system engagement history. The app can surface relevant content based on what the customer has done in every other channel.
None of that is possible without the resolution layer. Cleaning the existing data doesn't create the layer. A better CRM doesn't create the layer. Only a dedicated identity resolution engine does — and that's precisely what Salesforce Data Cloud provides.
The Three-Layer CDP Architecture We Proposed
Layer 1: Data Ingestion
The first layer is connecting all source systems to Data Cloud as authoritative feeds. This is not ETL in the traditional sense — it's not about moving data into a warehouse for reporting. It's about establishing continuous, event-driven flows that keep unified profiles current.
The source systems mapped during discovery included: the web CMS (behavioral events), the commerce platform (transactions), Salesforce CRM and Marketing Cloud, the LMS (course completions and certification milestones), the digital asset management system, the mobile app, and the data lake via API feeds.
For each source, three questions had to be answered: what data does it generate, how frequently can it send updates (real-time, near-real-time, or batch), and what identifier does it use for its records. The answers to these questions determine both the integration architecture and the resolution strategy.
One finding during this mapping exercise was significant: some feeds could be automated via API, others via scheduled file transfer, and some had no extraction mechanism at all and would require engineering work before they could contribute to the unified profile. Data readiness is not uniform across systems, and the CDP implementation timeline has to account for that variance.
Layer 2: Identity Resolution and Unified Profile
The second layer is where the structural work happens. Data Cloud ingests records from each source and runs them through its identity resolution engine. Records that share deterministic keys are merged immediately. Records that share probabilistic signals are scored and merged above a confidence threshold.
The output is a unified profile: a single customer record that aggregates attributes, events, and identifiers from every source system. For this client, a complete unified profile would show:
- Certification history and progression from the LMS
- Purchase history from the commerce platform
- Club membership status and tier
- Email engagement history from Marketing Cloud
- Web and app behavioral events
- CRM interaction notes and opportunity history
- Travel booking history
The desired future state was a unified view showing certification progress, travel interest, club status, email engagement, and purchase history — with real-time synchronization between the analytics data lake and the CDP engagement layer.
This is not just a richer contact record. It's a fundamentally different data object — one that crosses system boundaries and is maintained as a living profile that updates as the customer acts across any channel.
Layer 3: Activation
The third layer is where the unified profile generates value. Data Cloud doesn't replace Marketing Cloud or the CRM — it enriches them. Segments built in Data Cloud can be pushed to Marketing Cloud for campaign targeting. Calculated insights — engagement scores, churn risk scores, next-best-action signals — can be surfaced in the CRM for sales teams.
The activation layer enables real-time behavioral triggers: after a certification completion, the system can recommend a relevant next course and travel destination. Predictive modeling for churn or inactivity risk, next-course recommendation, and membership upgrade likelihood all become viable once the unified profile exists.
The important architectural distinction here is timing. Segments and triggers that run off Data Cloud unified profiles are current — they reflect what the customer has done across every system up to the moment the trigger fires, not what they had done as of the last batch export from the CRM. That currency is what makes real-time personalization technically possible rather than aspirational.
What Failed Without This Layer
The discovery workshop surfaced a specific historical data point that illustrated the cost of operating without identity resolution. One user had received 27 emails in 60 days due to the absence of audience exclusion and journey orchestration across systems.
That's not a campaign management failure. It's a direct consequence of operating multiple Marketing Cloud journeys against multiple partially-overlapping lists built from different source systems — each journey unaware that the others were targeting the same person. Without a unified identity layer, you have no mechanism to enforce cross-journey frequency caps because the person doesn't exist as a unified entity.
This is the kind of outcome that creates churn, reduces deliverability, and erodes trust with a customer base that the brand needs to retain. It's not addressable by improving campaign management processes. It requires fixing the underlying identity architecture.
The Snowflake Dependency
One architectural decision from the discovery process is worth examining separately: the relationship between the CDP and the existing data warehouse.
This client had invested in Snowflake as their analytics data warehouse. The data lake held significant historical behavioral data — engagement events, purchase history, web analytics — that predated the CDP implementation. That historical data is valuable for seeding unified profiles and training predictive models.
The integration architecture we recommended treated Snowflake as a data source for Data Cloud, not a replacement for it. Snowflake provides analytical depth. Data Cloud provides real-time identity resolution and activation. They serve different purposes and complement each other.
The practical implication: Data Cloud's identity resolution can reference historical signals from Snowflake when building unified profiles, but the activation layer needs to be event-driven from current system feeds, not batch-loaded from the warehouse. Latency in the ingestion pipeline directly limits the currency of personalization decisions.
This distinction — Snowflake as analytical depth, Data Cloud as activation engine — resolves a common confusion in organizations that have already invested in data warehouse infrastructure and aren't sure where CDP fits. They're not competing choices. They're different layers of the same architecture.
The Governance Question That Gets Skipped
Every CDP implementation eventually surfaces a question that nobody wants to own: who governs identity resolution decisions?
When the system merges two records probabilistically, it is making a judgment call. The confidence threshold at which records are merged is a policy decision, not a technical default. Setting it too low creates false merges — two different customers treated as one. Setting it too high leaves fragments — the same customer treated as multiple people.
The discovery process identified this explicitly: the client had attempted identity resolution internally and it had failed, likely due to weak matching rules. The governance question — who owns identity resolution policies — had never been formally assigned to a team.
This matters for implementation. Before a CDP can resolve identities reliably, someone has to define: what are the priority identifiers, what is the acceptable false-merge rate, who reviews merge decisions when the system flags uncertainty, and how are corrections propagated back to source systems.
These are not questions with universal answers. They depend on the business context, the regulatory environment, and the tolerance for error in downstream activations. But they have to be answered before implementation begins — not during it.
The Principle: You Cannot Personalize What You Cannot Identify
The central lesson from this engagement applies broadly, beyond the specific platform or client context.
Personalization investment — whether in Marketing Cloud journeys, website experience layers, or recommendation engines — is entirely contingent on the quality of the identity layer underneath it. You cannot build a meaningful customer journey across systems if you don't know, with confidence, that the person at each touchpoint is the same person.
A CRM that is well-configured but siloed cannot provide that. A data warehouse that is well-populated but batch-loaded cannot provide that. An analytics platform that tells you what happened in aggregate cannot provide that.
The identity layer is the prerequisite. Everything else — personalization, automation, predictive modelling, real-time engagement — is built on top of it. Getting there requires architecture decisions that most organizations defer because they're unglamorous: data mapping, identifier governance, probabilistic matching thresholds, consent management design.
But deferring them doesn't make the personalization problem go away. It just means that every journey you build, every segment you target, and every campaign you send is operating on partial information — confident-sounding guesses rather than unified knowledge.
Read Next
Once identity is resolved and unified profiles exist, the question becomes: how do you sequence the activation work across Sales Cloud, Data Cloud, and Marketing Cloud — and what happens if you get the order wrong?
→ The Right Order to Implement Salesforce: Why Sequence Matters More Than Speed
Axelerant works with enterprises on Salesforce Data Cloud implementation, CDP strategy, and identity architecture. If your team is navigating fragmented customer data and needs a clear path to unified profiles, we'd be glad to talk through how we approach it.

Bassam Ismail, Director of Digital Engineering
Away from work, he likes cooking with his wife, reading comic strips, or playing around with programming languages for fun.

Leave us a comment