 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.Working with Lovable, we built a unified discoverability architecture that serves crawlers, AI models, and humans from the same codebase.
The SPA Indexing Challenge
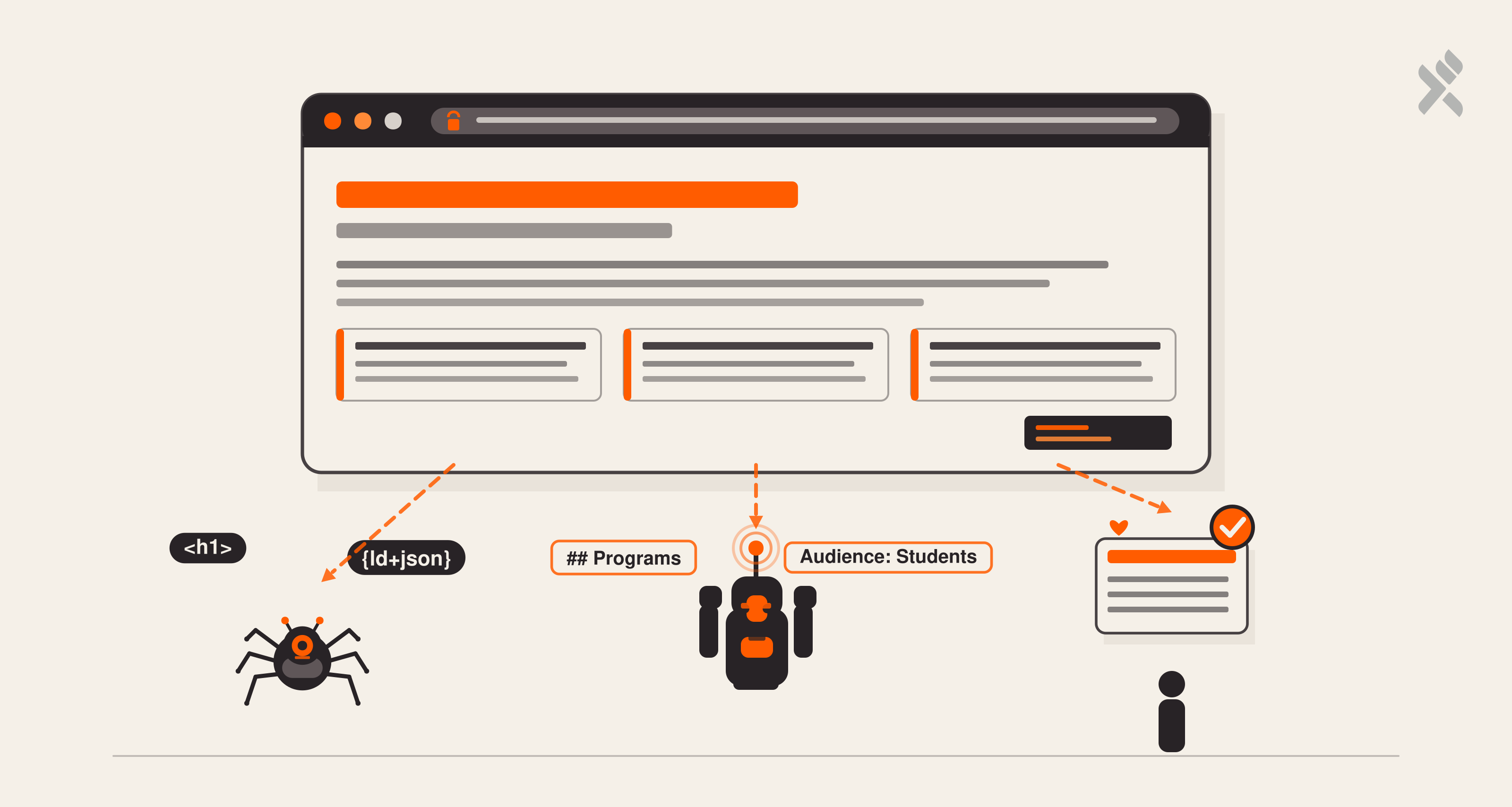
Our site is a React single-page application. That’s great for user experience (instant navigation, smooth transitions, rich interactivity), but it’s historically terrible for SEO. When Googlebot visits a React SPA, it initially sees an empty <div id="root"></div>. While Google’s renderer can execute JavaScript, it’s a two-phase process with no guarantees on timing.
We asked Lovable to solve this without migrating to a server-rendered framework. The solution was elegant: a static content fallback shell embedded directly in index.html.
The shell lives inside the React root element, so it’s immediately replaced on hydration.display:none and aria-hidden="true" ensure sighted users and screen readers never encounter duplicate content. But crawlers that parse raw HTML (including Googlebot’s first pass) immediately find rich, keyword-dense text with proper heading hierarchy.
This resolved Google Search Console’s “low text-HTML ratio” warnings overnight.
Structured Data: Speaking Schema.org
Raw HTML tells crawlers what text exists. Structured data tells them what it means. We built a reusable JSON-LD system through a shared component:
Simple wrapper, but the power is in the pre-built schema generators we created alongside it.
Organization Schema
Every page carries our organizational identity (name, logo, social profiles, founding year, and contact information), ensuring Google’s Knowledge Panel and AI models associate the correct metadata with our brand.
Course Schema
Each program page emits a Course schema with conditional pricing, duration, and provider information. The conditional spreading pattern (...(price && { ... })) is deliberate: not every program has public pricing, and emitting an empty Offer object would be worse than omitting it entirely.
Breadcrumb & FAQ Schemas
Navigation hierarchy through BreadcrumbList schemas helps Google display rich breadcrumb trails. Program pages with FAQ sections emit FAQPage schemas, which can trigger expandable Q&A directly in search listings.
Canonical Domain Strategy
We standardized on www.progressionschool.com as our canonical domain. Every URL across the entire system (sitemap entries, <link rel="canonical">, Open Graph tags, Twitter cards) uses the https://www. prefix explicitly.
Why this matters: If Google sees progressionschool.com and www.progressionschool.com as different URLs pointing to the same content, it splits our link equity. The canonical tag tells Google “this is the one true version.”
The Sitemap: Priority-Weighted Discovery
Our sitemap is a priority map that tells search engines where to allocate crawl budget:
|
Priority |
Pages |
Rationale |
|---|---|---|
|
1.0 |
Homepage |
Brand entry point, highest authority |
|
0.9 |
Audience pages |
High-intent landing pages |
|
0.8 |
Program pages, Library |
Conversion-critical content |
|
0.7 |
About, Individual workshops |
Supporting content |
|
0.3 |
Legal pages |
Required but low-SEO-value |
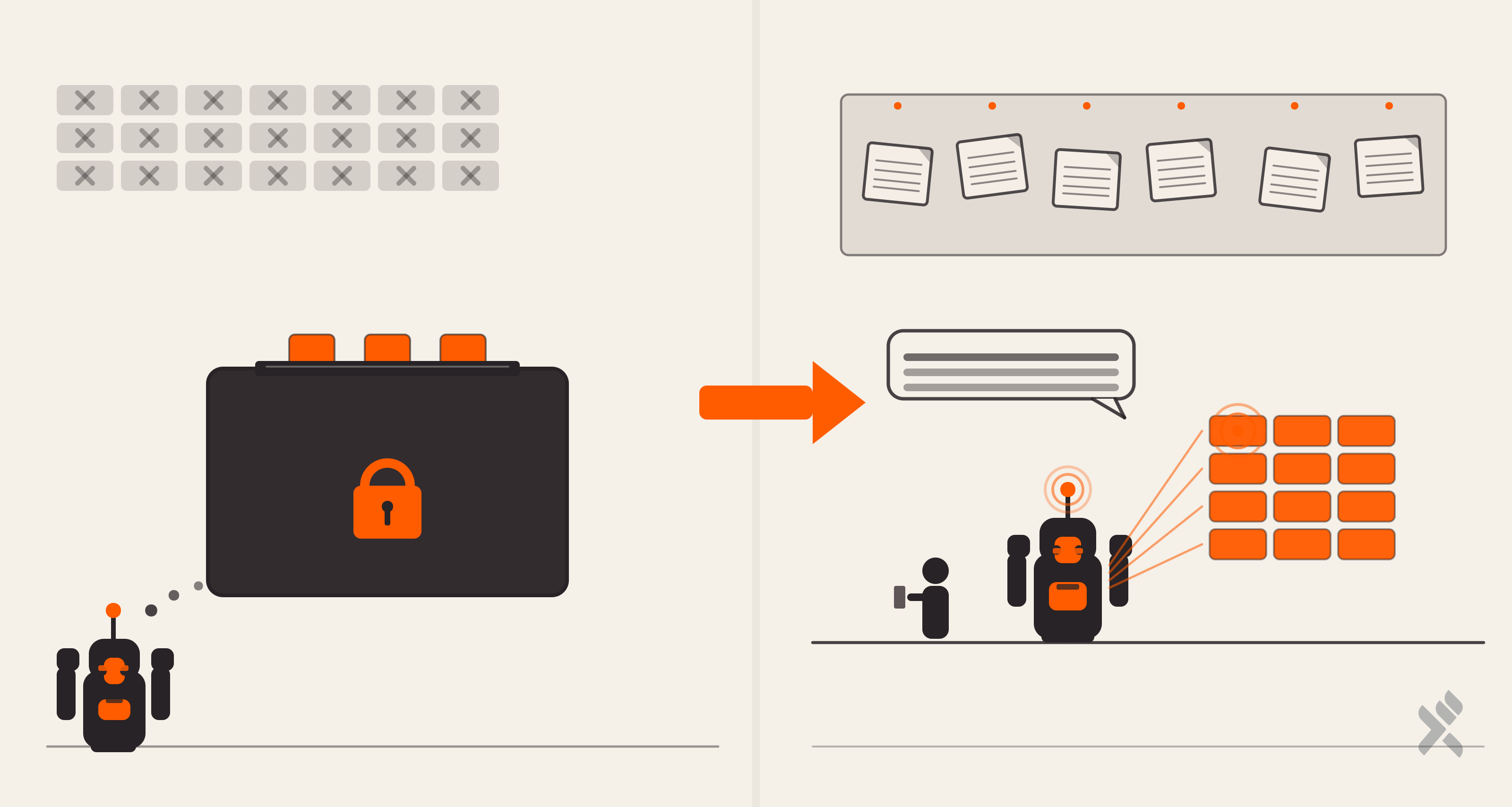
robots.txt: Welcoming Every Crawler
Most websites block AI crawlers. We took the opposite approach:
This is strategic. We want AI models to index our content. When someone asks ChatGPT “What’s a good AI internship program in India?”, we want our programs in the training data.
llms.txt: The AI-Native Discovery Layer
This is where our GEO strategy diverges from traditional SEO. We created public/llms.txt, a plain-text markdown file specifically designed for large language model consumption, with structured key-value metadata per program (Audience, Duration, Format, Outcome, URL).
The format choices are deliberate:
- Markdown: LLMs parse it better than HTML.
- Structured headers: Models can navigate to specific sections.
- Direct URLs: So AI assistants can cite sources.
- Natural language: Written for comprehension, not keyword stuffing.
We excluded llms.txt from robots.txt because the standard doesn’t officially support custom file references beyond Sitemap. AI crawlers discover it through convention (the /llms.txt path is an emerging standard).
The GEO Framework: Beyond Traditional SEO
|
Dimension |
SEO Approach |
GEO Approach |
|---|---|---|
|
Content Format |
HTML with heading hierarchy |
Markdown in llms.txt |
|
Structure |
Schema.org JSON-LD |
Key-value metadata per program |
|
Discovery |
sitemap.xml + robots.txt |
llms.txt + open crawler policy |
|
Authority |
Backlinks + domain age |
Consistent facts across all surfaces |
|
Rich Results |
FAQ, Course, Breadcrumb schemas |
Natural language Q&A in content |
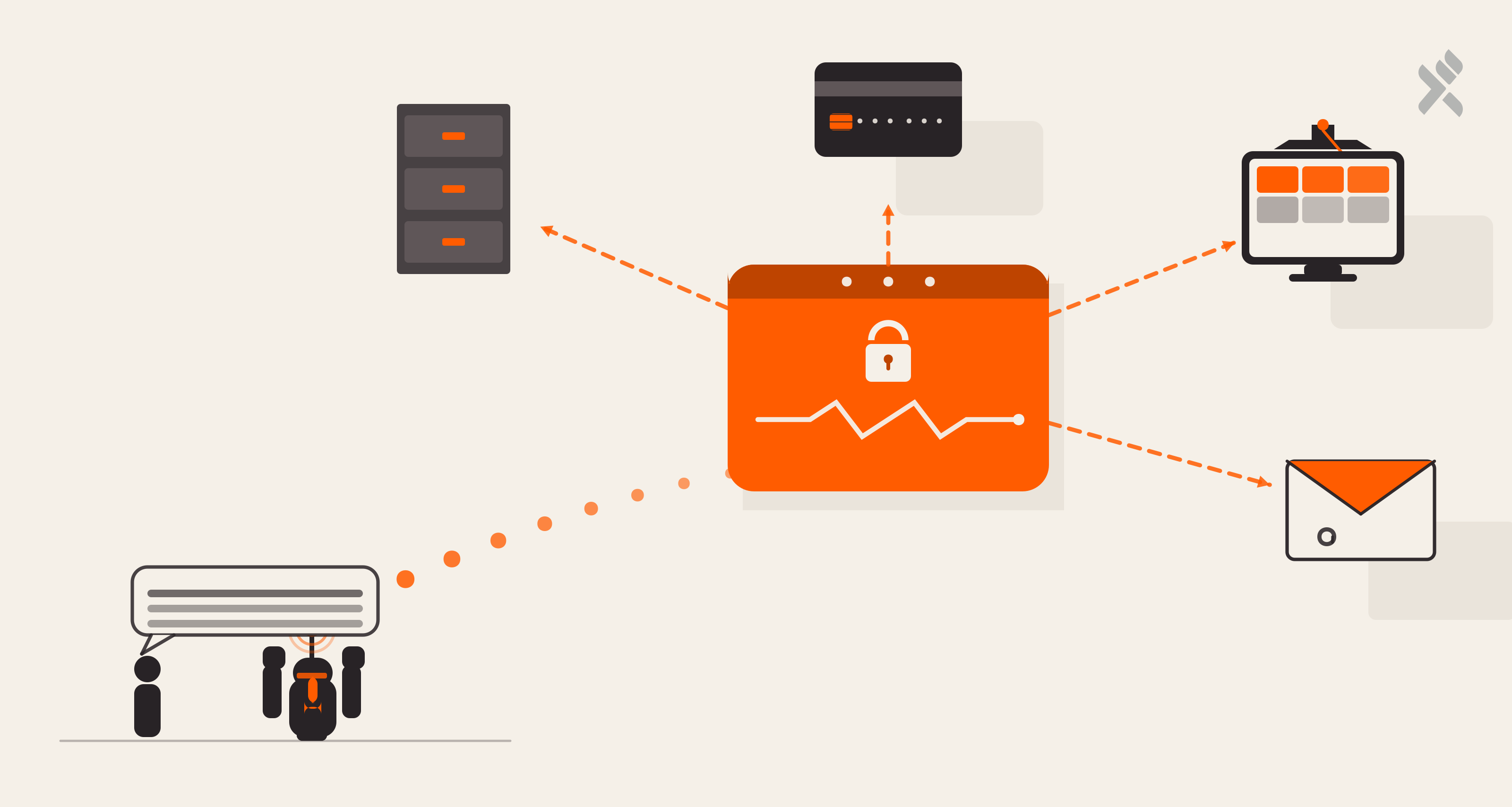
The key insight: consistency is the GEO ranking signal. If our JSON-LD says one thing, our llms.txt says another, and our page content says a third, AI models lose confidence in all three.
Performance As An SEO Signal
Google’s Core Web Vitals directly impact ranking. We use preconnect hints for Google Fonts and Razorpay, defer attributes on heavy third-party scripts, and favicon preloading. All of these serve both UX and SEO simultaneously.
What Lovable Made Possible
SEO is often treated as an afterthought because it’s tedious, not because it’s hard. With Lovable, we described the intent (“we need Course schema markup with pricing on every program page”) and received correct, spec-compliant implementations. When we said “crawlers are seeing empty HTML,” Lovable understood the SPA indexing problem and proposed the static fallback shell pattern. The GEO layer emerged from conversations about future-proofing: we described the goal and collaborated on the solution.
Building for a world where ChatGPT answers before Google does? Let’s design your discoverability layer together

Brahmpreet Singh, Senior Marketing Manager
Brahmpreet Singh is a marketing professional with over a decade of experience in SaaS and B2B content strategy. He enjoys blending research-driven insights with creative storytelling to support meaningful growth in organic traffic and lead generation. Brahmpreet is dedicated to building thoughtful, data-informed marketing strategies that resonate with audiences and drive long-term success.

Leave us a comment