
 We respect your privacy. Your information is safe.
We respect your privacy. Your information is safe.Velocity detection tells you something happened fast. It does not tell you whether it matters.
A transaction going through at a normal dollar amount is unremarkable on its own. But if the implied exchange rate is 4% off the market rate at that exact moment, that’s a signal. A post going viral in 30 seconds is interesting. But if the users driving it all have reputation scores below 0.4, that’s coordinated manipulation. A sensor reading might look fine in isolation, until you compare it to the rolling mean for that device over the last five minutes and find it’s three standard deviations out.
These are correlation problems. The primary event arrives on one stream; the context that gives it meaning arrives on another. They are linked by a shared key, a currency pair, a user ID, a sensor ID, and the question is always some version of: does this event, when held up against recent context, cross a line?
This post is the third in a four-part series on engineering a real-time pattern detection engine with Apache Flink (PyFlink) and Kafka. Part 1 covered Threshold Pattern and Rule Reload. Part 2 covered the Velocity Pattern, how to aggregate events across a sliding window per key using KeyedProcessFunction and ListState, and how to route velocity-triggered events to a downstream stage via synthetic topic tagging (avoiding side outputs for AWS MSF compatibility). At the end of Part 2, we noted that velocity detection answers “how fast” but not “what happened together.” Here, in Part 3, we pick up exactly where that left off. We focus on the Correlation Pattern, evaluating primary events (e.g. transactions, posts) against a context stream (e.g. FX rates, user reputation) within a lookback window, with optional velocity pre-filtering for compound patterns like AstroTurf detection.
What The Correlation Pattern Does
Correlation rules answer: “Does this primary event match a condition when we look at the context for the same key in a lookback window?” For example:
- Transaction Vs. FX Rate: Flag when a transaction’s implied rate deviates from the market rate (context = last rate for that currency pair).
- Sensor Vs Rolling Baseline: Flag when a reading deviates from a rolling mean (e.g., z-score > 3).
- Velocity x Reputation (AstroTurf): Flag when a high-velocity hashtag is driven by low-reputation users: a velocity rule filters “hot” posts (e.g., count ≥ 30 per hashtag in say a min) and tags them for routing; the job then filters these records into the correlation pipeline; a correlation rule consumes that stream and checks user reputation from a context topic. Only “high velocity + low reputation” is written to the sink.
The engine keeps a time-ordered buffer of context per correlation key (e.g., per user_id). When a primary (event) arrives, it resolves context (last value, mean, or mean±std) in the lookback window, computes a metric (e.g., ratio_deviation, z_score, or direct comparison), and emits if the condition holds. If context is missing when the primary event arrives and resolution is last, we can buffer the primary event and re-evaluate when context for that key arrives.
In this post, we will cover:
- Correlation Rule Schema: Required and optional fields, context_resolution, metric, and optional velocity_filter_rule_id
- Implementation: How we use Flink’s keyed stream and ListState to join two streams (primary + context) and evaluate the rule
Flink Concepts Used In This Post
|
Concept |
What It Is |
Official reference |
|
key_by(key_selector) |
Partitions the stream by a key so that all records with the same key go to the same task. For correlation we key by (rule_id, correlation_key_value) so primary and context for the same key meet in one KeyedProcessFunction. |
|
|
KeyedProcessFunction |
Process function that runs per key and has access to keyed state (e.g. ListState). We use it to hold the context buffer and (for resolution last) a pending-primaries buffer. |
|
|
ListState |
Keyed state holding a list of elements. We use one ListState for (timestamp_ms, value) context events and one for (event_ts_ms, event_json) pending primaries (when context is missing and resolution is last). |
|
|
DataStream.union(...) |
Combines two or more streams of the same type into one. We union primary stream, context stream, and (optionally) filtered velocity-to-correlation stream so that one keyed operator receives (key, rule_json, tag, event_json) with tag primary or context. |
|
|
BroadcastProcessFunction |
Same as in Part 1 and 2: we use it to route events to correlation by reading rules from broadcast state and emitting (key, rule_json, tag, event_json). Primary and context streams are each connected to broadcast rules and then unioned. |
Correlation Rule Schema
Correlation rules use the common rule fields and add a context topic and lookback instead of a threshold-style conditions list.
Required Fields
|
Field |
Description |
|
rule_type |
"correlation" |
|
source_topic |
Kafka topic for primary events (e.g. |
|
context_topic |
Kafka topic for context events (e.g. |
|
correlation_key |
Field linking primary and context (e.g. |
|
window_size, window_unit |
Lookback window for context (e.g. 5 minutes). Only context with timestamp in [event_ts - window, event_ts] is used. |
|
context_resolution |
How to turn the context window into one value: last (last value at or before event time), mean, or |
|
context_value_field |
Field on context events used as the context value (e.g. reputation, rate). |
|
timestamp_field |
Timestamp field on both primary and context events. |
|
condition |
Single condition: { "operator": ">", "value": <number> } (or <, >=, <=, ==, !=). Applied to the computed metric or to the context value for metric: direct. |
Optional Fields (Common)
|
Field |
Default |
Description |
|
metric |
direct (when omitted) |
|
|
event_value_field |
— |
Field on primary used in the metric; required for ratio_deviation, difference, and z_score. |
|
emit_mode |
both |
event, context, or both — what to include in the emitted detection. |
|
context_type_field, context_type_value |
— |
Filter context events by type (e.g. only |
|
velocity_filter_rule_id |
— |
If set, only primary events that passed this velocity rule are evaluated (AstroTurf). That velocity rule should have |
|
max_context_age_seconds |
— |
Ignore context older than this (seconds). |
|
min_context_points |
— |
Minimum context points required for mean/mean_std. |
|
watermark_delay |
5 |
Allowed lateness (seconds) for late-arriving context. |
Context Resolution And Metric
|
context_resolution |
Meaning |
Typical Use |
|
last |
Use the latest context value at or before the event’s timestamp (LOCF). Supports buffering of primaries when context is missing. |
Last FX rate, last user reputation. |
|
mean |
Mean of context values in the lookback window. |
Baseline level. |
|
mean_std |
Mean and standard deviation (for z_score). |
Anomaly vs baseline. |
|
Metric |
Formula/Meaning |
Condition Example |
|
ratio_deviation |
|event_value / context_value - 1| |
> 0.02 |
|
difference |
event_value - context (e.g. mean) |
> 5 |
|
z_score |
(event_value - mean) / std |
> 3 |
|
direct |
Condition applied to context value only |
reputation < 0.4 |
Example Correlation Rules
Both patterns rely on the same underlying mechanism: two streams, one shared key, and a keyed state buffer that holds context until a primary event arrives to be evaluated against it.
Example 1: Transaction Vs FX Rate
Flag when the transaction’s implied rate deviates from the market rate by more than 2%:
Primary and context are joined by currency_pair. We use the last rate at or before the transaction’s timestamp, compute ratio_deviation (|tx_implied_rate / market_rate - 1|), and emit when it exceeds 0.02.
Example 2: AstroTurf (Velocity Filter + Correlation)
Only evaluate posts that already passed a velocity rule (e.g. “≥5 posts for this hashtag in 30s”); then check user reputation from context. Emit only when reputation < 0.4:
Primaries for this correlation rule only come from the Velocity Correlation Branch (the stream filtered for the _VELOCITY_TO_CORRELATION_ROUTE marker).
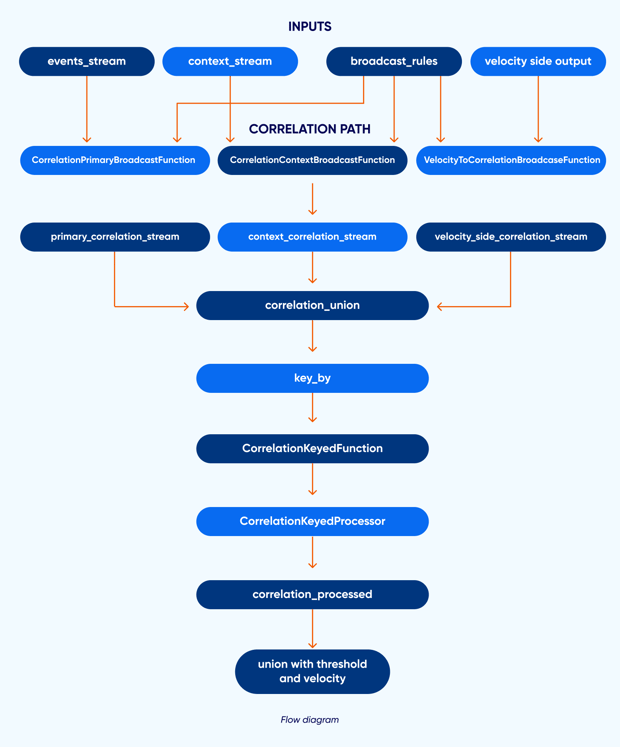
How We Built It: Two Streams, One key, Keyed state
We used Flink’s union to combine three streams into one: (1) primaries from the main events topic, (2) context from the context topic, and (3) events from the Velocity Correlation Branch (marked with _VELOCITY_TO_CORRELATION_ROUTE). Each stream is produced by a BroadcastProcessFunction that reads rules from broadcast state and emits (key, rule_json, tag, event_json) with tag primary or context. We then key_by the first element so that all records for the same (rule_id, correlation_key_value) go to the same task. A KeyedProcessFunction (CorrelationKeyedProcessor) holds two ListStates: one for context (timestamp_ms, value) and one for pending primaries (when context is missing and resolution is last). In this context, we append and evict old entries, then drain pending primaries; on primary, we resolve context, compute the metric, evaluate the condition, and emit or buffer.
Primary And Context Streams
We use two BroadcastProcessFunctions: one for the events stream (CorrelationPrimaryBroadcastFunction) and one for the context stream (CorrelationContextBroadcastFunction). Each emits (key, rule_json, tag, event_json) only for correlation rules; the key is rule_id|correlation_key_value. The context stream is built from a separate Kafka source for context_topic. A third broadcast function (VelocityToCorrelationBroadcastFunction) turns velocity side-output events into the same (key, rule_json, "primary", event_json) shape for correlation rules that have velocity_filter_rule_id. We union primary stream, context stream, and velocity-side stream so one keyed operator sees both primaries and context for each key.
Keying And Single-Keyed Operator
We used correlation_union.key_by(lambda x: x[0]) so that every function (key, rule_json, tag, event_json) with the same key is processed by the same instance of CorrelationKeyedFunction, which delegates to CorrelationKeyedProcessor. The processor’s process_element receives (tag, event_json): if tag is context it appends to the context ListState and evicts entries older than the lookback window, then re-evaluates any pending primaries; if tag is primary it resolves context (last/mean/mean_std), computes the metric, evaluates the condition, and either emits a detection or (for resolution last when context is missing) adds the primary to the pending ListState.
Context Resolution And Oending Primaries
We used ListState for the context buffer: (timestamp_ms, value). Lastly, we took the latest (t, v) with t ≤ event_ts; for mean / mean_std, we computed mean (and std) over values in [event_ts - window, event_ts]. When resolution is last, and no context exists yet, we buffer the primary in a second ListState (event_ts_ms, event_json) and drain it when a context event for that key arrives — so arrival order of primary vs context does not have to be fixed.
4. Code snippets
Two snippets cover everything that matters: how state is declared, how events are processed by tag, and how the streams are wired together.
State In CorrelationKeyedProcessor (Open)
We used two ListStates: one for context (timestamp_ms, value) and one for pending primaries (event_ts_ms, event_json). Flink’s ListStateDescriptor and get_list_state give us the keyed state.
Processing Context Vs Primary
In process_element we branch on the tag. For context we append (ts_ms, value) to _context_state, evict entries older than (now - window), and drain pending primaries. For primary we resolve context (e.g. _get_last_context_at_or_before), compute compare_value (metric or direct), and call evaluate_condition(compare_value, operator, value); if it matches we build the enriched detection and out.collect((sink_topic, json.dumps(enriched))). If context is missing and resolution is last, we add the primary to _pending_state instead of emitting.
Wiring: union and key_by
End-To-End Flow For Correlation
- Events (and rules) are as in Part 1. A separate Kafka source reads context from context_topic (e.g. context.raw).
- Primary Stream: Events are connected to broadcast rules; CorrelationPrimaryBroadcastFunction emits (key, rule_json, "primary", event_json) for each correlation rule (key = rule_id|correlation_key_value).
- Context Stream: Context events are connected to broadcast rules; CorrelationContextBroadcastFunction emits (key, rule_json, "context", event_json) for each correlation rule.
- Velocity → Correlation (Optional): Events that passed a velocity rule (with
emit_to_sink: false) are filtered into the correlation branch. TheVelocityToCorrelationBroadcastFunctionthen processes these as primary events for any rule with a matchingvelocity_filter_rule_id. VelocityToCorrelationBroadcastFunction emits (key, rule_json, "primary", event_json) for correlation rules that have velocity_filter_rule_id set. - We combined the three streams and key_by the first element so that all (key, rule_json, tag, event_json) for the same key go to the same CorrelationKeyedFunction. The function delegates to CorrelationKeyedProcessor, which maintains context buffer and pending primaries in ListState, resolves context, computes the metric, and emits when the condition holds.
correlation_processedis merged with threshold and velocity results and written to the sink.
Flow diagram:
Example: AstroTurf Matching Behavior
Setup: Velocity rule hashtag_velocity (count ≥ 5 per hashtag in 30s, emit_to_sink: false). Correlation rule low_reputation_user with velocity_filter_rule_id: "hashtag_velocity", correlation_key: "user_id", context_resolution: last, metric: direct, context_value_field: "reputation", condition reputation < 0.4.
Flow:
- Many posts for #crypto_viral arrive; the velocity rule fires and emits those events with the
_VELOCITY_TO_CORRELATION_ROUTEmarker. These are routed internally to the correlation engine; nothing is written to the Kafka sink topic yet. - VelocityToCorrelationBroadcastFunction turns each into (key=low_reputation_user|user_003, rule_json, "primary", event_json) and feeds the correlation union.
- Context topic has user reputation: e.g. user_id: "user_003", reputation: 0.28. CorrelationContextBroadcastFunction emits (key=low_reputation_user|user_003, rule_json, "context", context_json).
- CorrelationKeyedProcessor for key low_reputation_user|user_003 receives context and appends (timestamp, 0.28) to the context buffer. When it receives the primary, it resolves context (last reputation = 0.28), compares 0.28 < 0.4 → true, and emits one detection to the sink (e.g. events.processed).
- Posts from high-reputation users (e.g. reputation 0.9) do not satisfy the condition and are not emitted. Only “high velocity + low reputation” produces sink records.
Building Context-Aware Detection Into Your Stream
The correlation pattern completes the core of what this rules engine can express. Here's what we covered in this post and where it fits in the broader picture:
- Correlation rules evaluate primary events against context in a lookback window by
correlation_key. We supportcontext_resolution(last, mean, mean_std) andmetric(ratio_deviation, difference, z_score, direct). A single condition is applied to the computed value or to the context value. - Implementation: We used Flink's
unionto combine primary stream, context stream, and (optionally) velocity-side stream into one, thenkey_byso that all records for the same(rule_id, correlation_key_value)are processed by oneKeyedProcessFunction. We use twoListStates: context buffer (timestamp, value) and pending primaries (for resolutionlastwhen context arrives late). Broadcast functions route events to(key, rule_json, tag, event_json);CorrelationKeyedProcessorresolves context, computes the metric, and emits when the condition holds. - Velocity filter (AstroTurf): A velocity rule with
emit_to_sink: falsetags events for the correlation branch; correlation rules withvelocity_filter_rule_idconsume this filtered stream via the routing marker. Only primaries that passed the velocity rule are evaluated against context, so you can express "high velocity and low reputation" in two composable rules.
Together, these three patterns, threshold, velocity, and correlation, give you a composable detection layer that handles the full range of real-time anomalies: the obvious spike, the fast accumulation, and the cross-stream signal that only means something in context. The same rules engine, the same broadcast state reload mechanism, the same Kafka-native routing, just a progressively richer set of pattern types sitting on top.
For the full rule reference and additional examples, see the Rules Reference and Correlation Pattern docs, and the complete documentation tree for deeper coverage.
Building detection pipelines at this layer, async stream joins, stateful lookback windows, and compound velocity-correlation patterns require architectural decisions that compound over time. If your team is scaling real-time data engineering on PyFlink, Kafka, or AWS MSF, talk to our engineering team at Axelerant. We've built this in production and can help you get there faster.

Qais Qadri, Senior Software Engineer
Qais enjoys exploring places, going on long drives, and hanging out with close ones. He likes to read books about life and self-improvement, as well as blogs about technology. He also likes to play around with code. Qais lives by the values of Gratitude, Patience, and Positivity.

Leave us a comment